

Linux系统性能问题排查思路(面试必备)
主要方便排查系统问题,了解性能优化的思路和方法,掌握常用的 linux 性能工具。
CPU
常用的分析 CPU 使用情况的工具包括 top 、 ps 和 pid…

全栈声明式可观测:KubeVela开箱即用且灵活定制的云原生应用洞察
KubeVela 是一个开箱即用的现代化应用交付与管理平台。本文我们将聚焦 KubeVela 的可观测体系,介绍云原生时代的可观测挑战及 KubeVel…

ElastAlert 基于Elasticsearch的监控告警
Elastalert是Yelp公司用python2写的一个报警框架(目前支持python2.6和2.7,不支持3.x).
GitHub地址为 https://g…
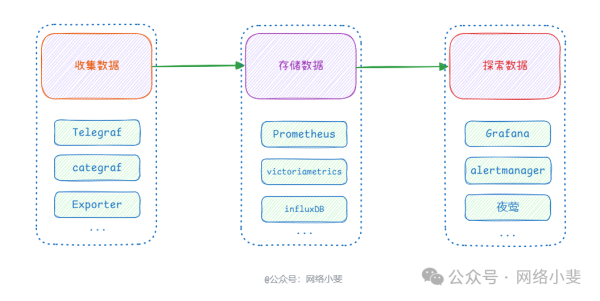
打造融合式监控平台满足99%企业对监控告警的需求
大家好,我是小斐呀。
在前面的文章中分享了一些基于 Prometheus 体系如何对网络设备的监控告警案例,后台私信也收到了很多粉丝朋友们的一些疑问和咨询,随着…


一次访问Redis延时高问题排查与总结
作者抽丝剥茧的记录了一次访问Redis延时高问题的排查和总结。
背景
20230308 在某地域进行了线上压测, 发现接口RT频繁超时, 性能下降严重, P5…



看了那些大厂做的监控,反观自己我陷入了沉思…
大家好,我是小斐呀。
7月26日,我有幸受邀出席了由中国计算机学会主办的第二届 CCF 夜莺开发者创新论坛。在此次会议中,我分享了一些关于网络可观测性的思考与实…
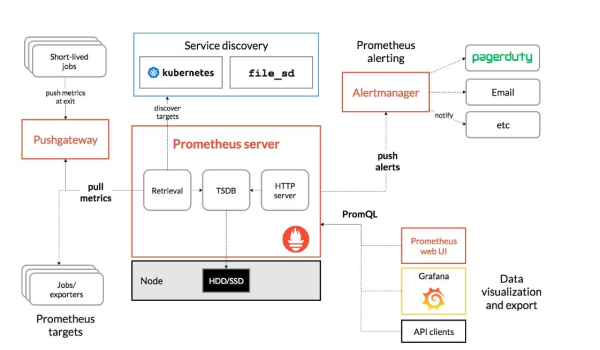
【完整教程】Prometheus+Grafana监控系统搭建
一. 概述
1.1 Grafana介绍
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。它主要有以…
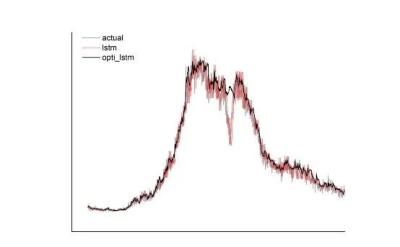
干货 | 故障召回率提升34%,携程智能异常检测实践
作者简介
零一,携程算法工程师,专注于智能告警、容量管理、根因定位等领域。
一、背景
携程作为在线旅游公司,对外提供机票、酒店、火车票、度假等丰富的旅游产品,其…
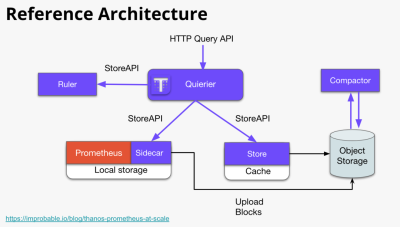
可观测平台如何存储时序曲线?滴滴实践全历程分享
滴滴的时序曲线量从 2017 年 到 2023 年增长了几十倍。整个过程中我们不断地调整和改进以应对这样的增长。例如时序数据库的选型从最初的 InfluxDB,…
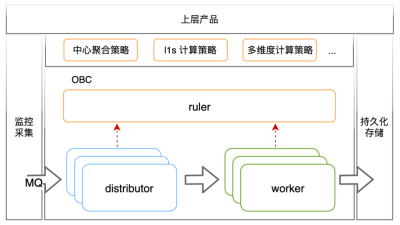
滴滴可观测平台 Metrics 指标实时计算如何实现了又准又省?
在滴滴,可观测平台的 Metrics 数据有一些实时计算的需求,承载这些实时计算需求的是一套又一套的 Flink 任务。之所以会有多套 Flink 任务,是因为…


三万字长文:JVM内存问题排查Cookbook
阿里妹导读
本文主要系统性地整理了排查思路,为大家遇到问题时提供全面的排查流程,不至于漏掉某些可能性误入歧途浪费时间。
一、前言
本文又名《如何让对JVM一…

10倍性能提升-SLS Prometheus 时序存储技术演进
阿里妹导读
本文将介绍近期SLS Prometheus存储引擎的技术更新,在兼容 PromQL 的基础上实现 10 倍以上的性能提升。同时技术升级带来的成本红…
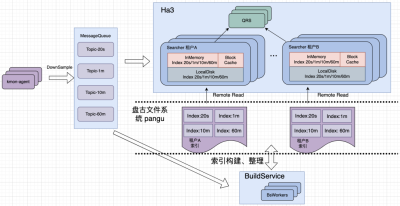
阿里技术:Khronos: 面向万亿规模时间线的性能监控引擎建设实践
阿里巴巴智能引擎事业部自研的 Khronos 系统是阿里内部接入规模最大的性能数据存储引擎。Khronos 支持动态生命周期的存储计算分离架构,采用 schem…


实战总结|一次访问Redis延时高问题排查与总结(续)
本文是一次访问Redis延时高问题排查与总结的续篇,主要讲述了当时没有发现的一些问题和解决方案。
背景
在今年4月份,笔者写的 一次访问Redis延时高问题排…
