
滴滴 OrangeFS 数据湖存储关键技术揭秘! - 滴滴技术
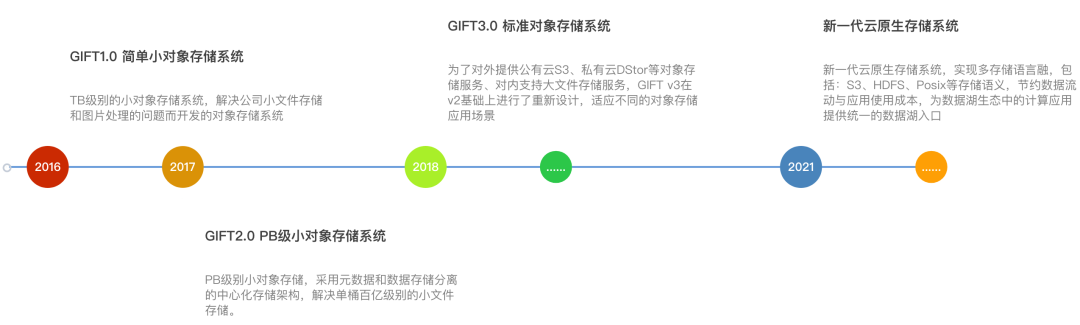
2015年,滴滴为解决小文件和图片的存储,成立 GIFT 小对象存储项目。伴随着业务不断成长,我们面临的挑战也越来越多,经历多次非结构化存储架构演进,具体如下图所示:
随着公司不断发展,滴滴的业务有两个发展的趋势:云原生技术战略和新业务涌现,都给存储系统带来了新的挑战。
在云原生战略中,业务的极致弹性是提高资源利用率降低成本的一个目标。保障极致弹性的基础是容器的轻量化,而要实现容器的轻量化就必须实现存算分离。但目前弹性云的容器都是使用本地盘来存储业务日志或数据,这样天然和宿主强绑定,无法实现存算分离,且宿主机的磁盘利用率只有30%左右,容器漂移后数据还会出现易丢失现象。如果是业务日志数据,还需要通过采集方式存储到 HDFS 中,即:本地盘一份,HDFS 一份,双份存储,成本高。
同时,滴滴的自动驾驶,机器学习,国际化,金融等业务的不断发展,涌现了很多边端上传大量数据、服务端训练的场景,而边端和服务端对存储的需求又有一定的差异。例如:机器学习的训练场景主要是通过 S3 协议上传数据到滴滴 GIFT 对象存储系统中,通过类似 S3FS 方式挂载文件系统进行训练,这种模式缺点是处理流程长,延迟高,性能无法满足业务需求,且非完整的文件系统,对于 apend 或 rename 操作非常重。
解决思路
为了满足云原生技术战略和新业务的涌现需求,弹性云 K8S 通过 Posix 协议挂载网络盘写入网约车日志或数据,并通过 S3 或 HDFS 协议并发查询日志,解决了数据因飘移造成丢失、采集链路长(也就是通过 S3 或 HDFS 协议直接读取 Posix 写入日志数据)等问题,同时管理弹性云磁盘又能提供磁盘利用率。而机器学习的训练场景可以通过 S3 协议上传数据,Posix 协议去挂载训练,也可以解决流程长,延迟高问题。
我们需要提供一套支持多协议融合的云原生分布式存储系统,内部称之为:OrangeFS 云原生数据湖存储系统,整个系统核心技术主要包括:
- 多协议融合:采用统一文件组织结构,在这种结构基础上实现 Posix、S3、HDFS 三种不同存储协议融合。
- 云原生:基于 CSI 插件可以快速地在 Kubernetes 上使用 OrangeFS。
- 多云存储引擎:为了保证云上云下架构一致,应用于不同的场景,云下可以使用滴滴自研的 DFS 数据存储服务,线上可以使用 AWS S3、阿里云 OSS、腾讯云 COS、谷歌云等等。
- 多租户:为了降低业务部署成本,我们支持多租户管理,提供细粒度的租户隔离策略。
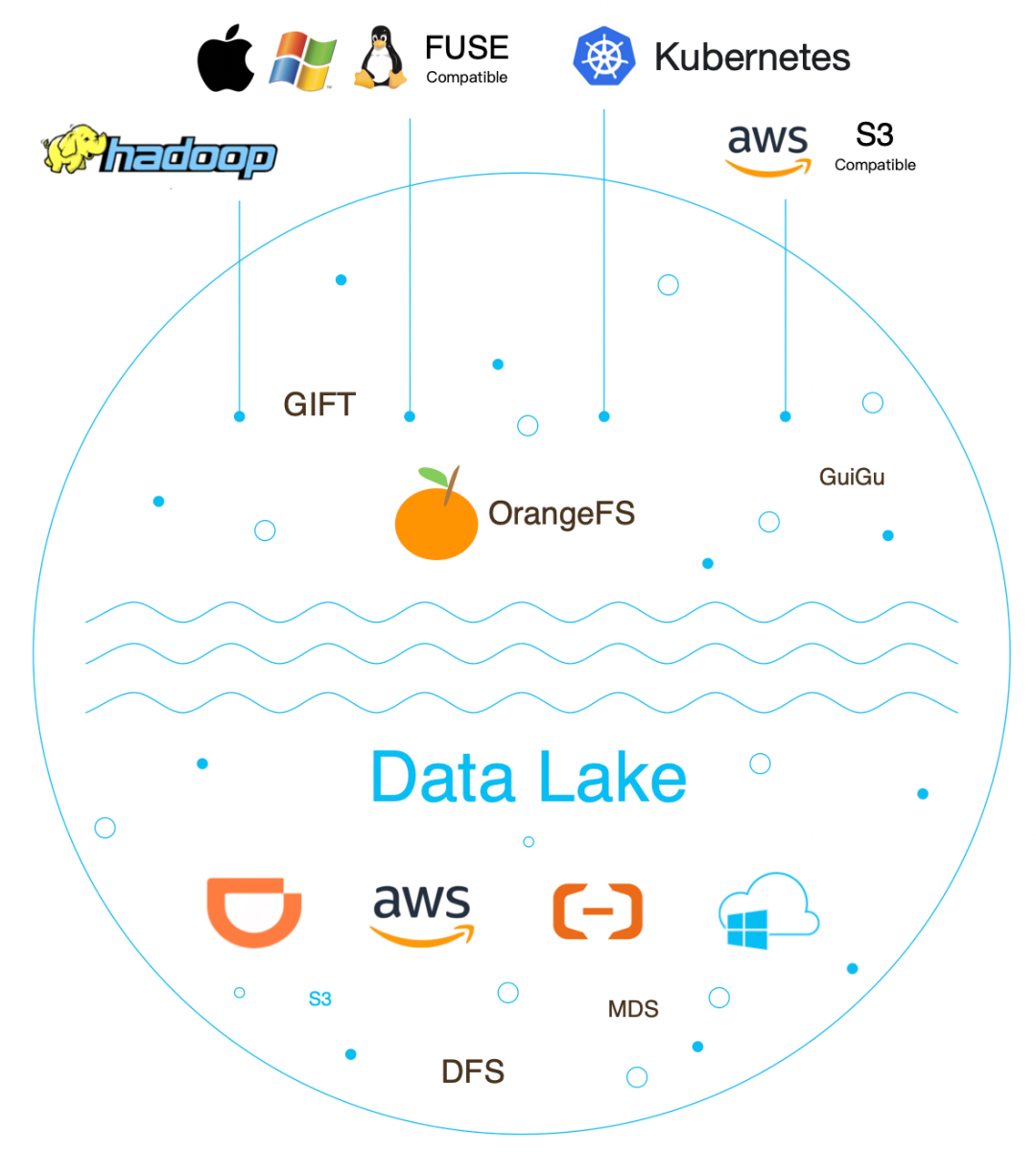
核心技术
1. 文件组织结构
为了减少数据流动成本,我们参考并学习行业通用的多协议融合模式,主要有2种,第一种:在对象存储系统基础上构建文件系统,比较常见 S3FS。第二种:采用统一文件组织结构,在这种结构基础上实现 Posix、S3、HDFS 三种不同存储协议,例如:JuiceFS、CubeFS。
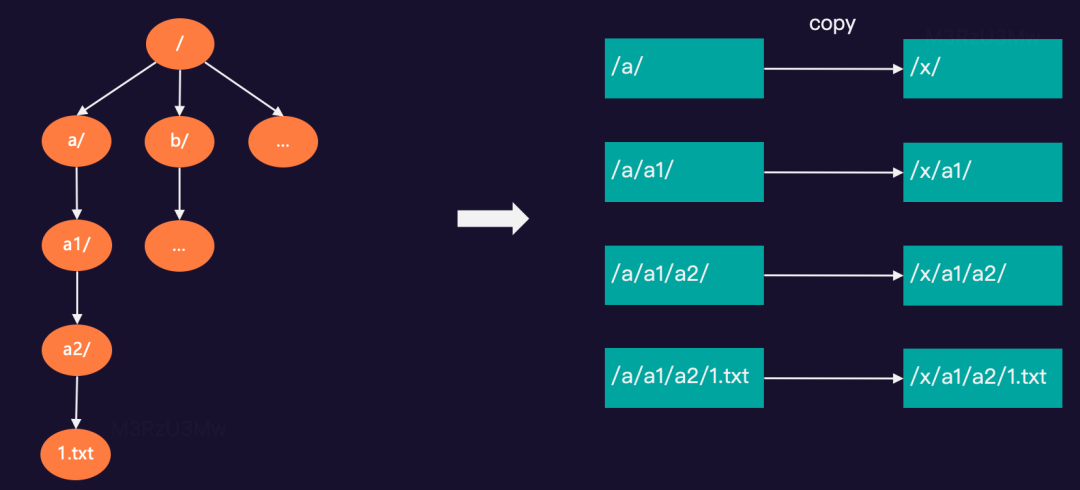
基于AWS S3对象存储实现的 S3FS,可以把 S3 bucket 挂载到系统中以 POSIX 方式访问,但无法提供原子的 rename和文件的随机写操作。例如:在 ofs-test 桶中有“/a/a1/a2/1.txt…”等文件,需要 rename 根目录下的a/文件夹为x/,具体如下图所示:
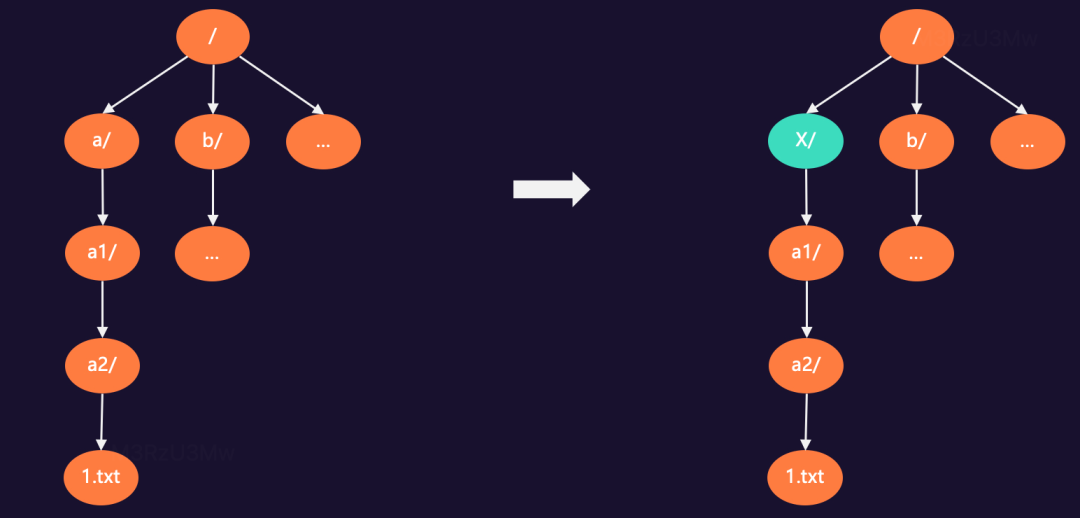
采用统一文件组织结构模型,在这种结构基础上实现不同存储协议,可实现真正的文件系统和对象存储系统。例如:通过ofs-test 桶中有“/a/a1/a2/1.txt…”等文件,通过文件系统 rename 根目录下的a/文件夹为x/,只需要修改目录树节点的名称,其他无需变更。
为了提供系统读写的并发性能,我们把一个文件拆成多个固定大小段,我们称之为 Chunk。每个Chunk内部都会存在多次写入或修改的可能,我们把每次写入或修改不固定的大小块称之为 Blob(Binary Large Object)。一个 Blob 是由多个固定长的数据块组成,我们称之为 Block。具体如下图所示:
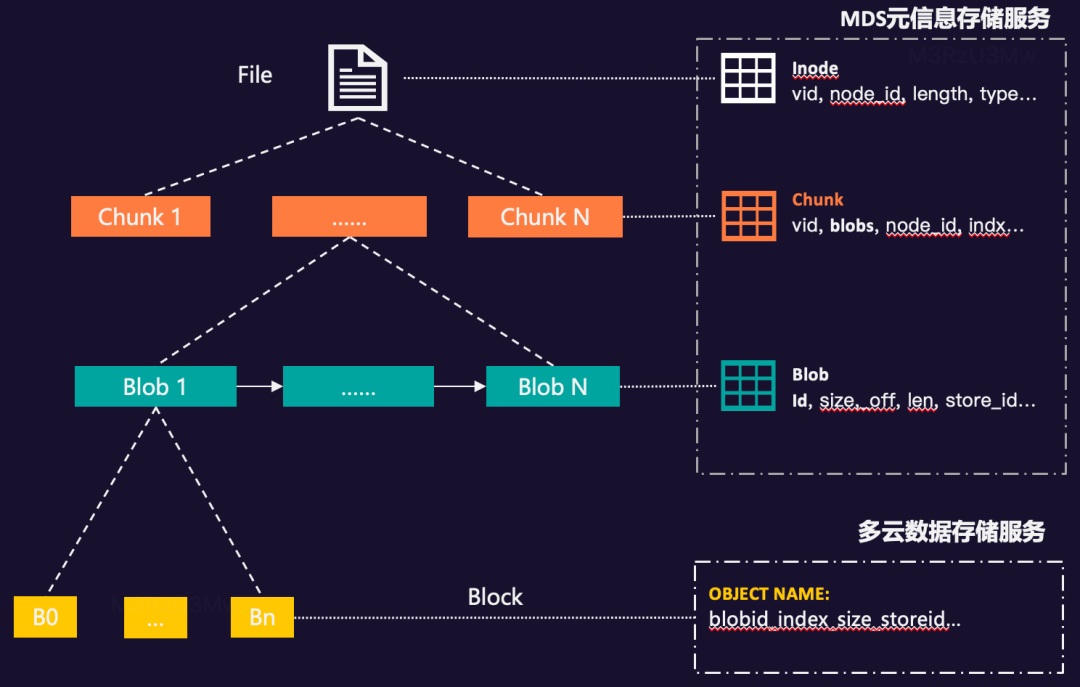
Chunk 和 Blob 数据信息我们存储到自研的 MDS 元信息存储服务中,而 Block 分块,我们存储在自研的 DFS 数据存储服务或公有云的S3、cos、oss等产品中。
1.1 写组****织结构
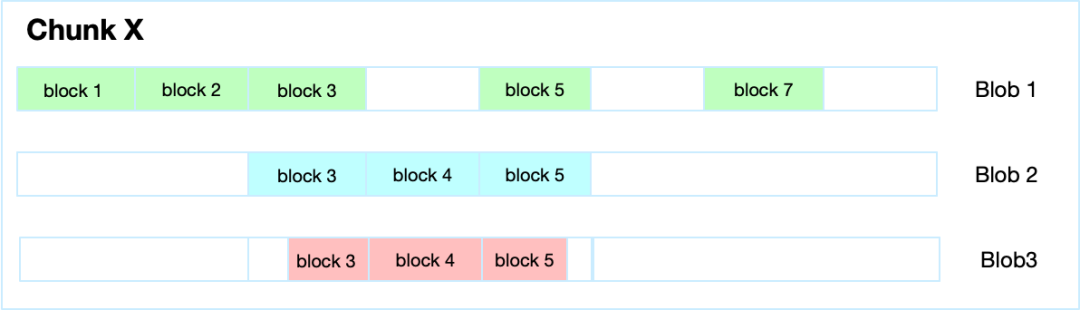
文件在写场景时,提高性能减少Blob数量,每个 Chunk 默认只生成一个 Blob,每次直接写入对应的数据块,我们称之为 block。具体如下图所示:

当业务写入或修改的内容对应的数据块与上一个Blob有重叠时,就会生成新的Blob,只要数据不重叠,那么就不生新的 Blob。如上图,在 block3 到 block5 之间插入一个新的数据块,就会生成一个新 Blob,具体如下图所示:

当业务写入数据刚好介于 block3 中间部分,那么这类场景也是生成新的 Blob,来保证每次写入都是顺序写,具体如下图所示:
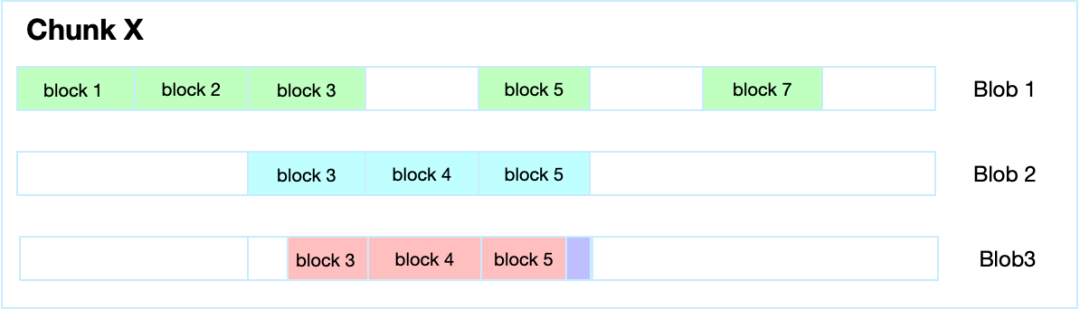
当业务写入的数据刚好是在 Block5 数据块上,而且新写入的数据与 Block 5 原内容不重叠,那么可以做 append 操作,具体如下图所示:
1.2 读组织结构
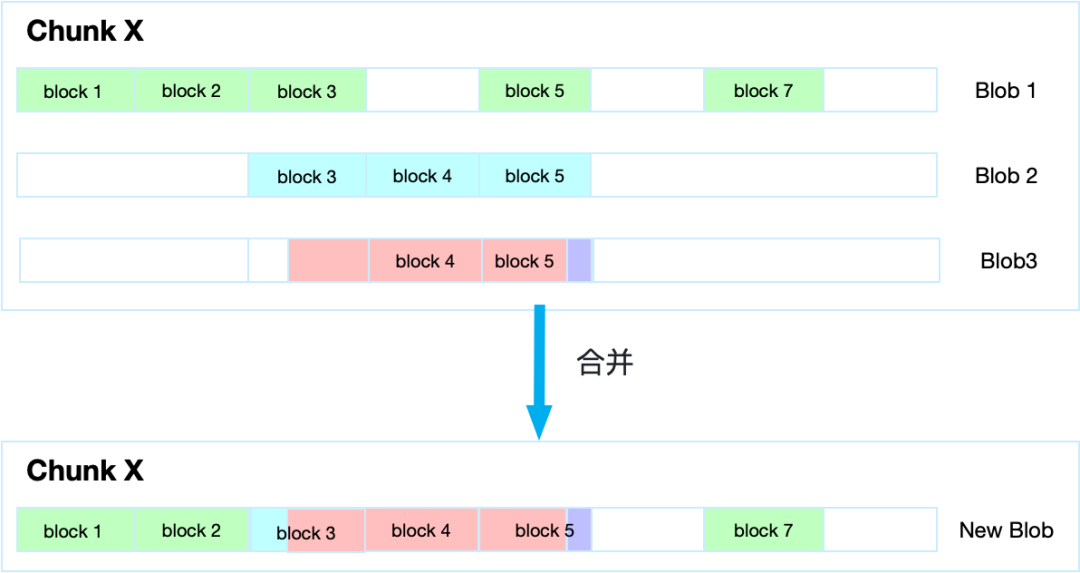
文件在读的场景时,读取到某个 Chunk 时,会将所有的 Blob 进行合并,获取到一个新的 Blob,再将新的 Blob 对应的数据块 Block 返回给上层调用服务。具体如下图所示:
2. 多协议融合
我们已知文件组织结构设计后,那如何在统一的文件组织结构上实现不同的协议?对于 OrangeFS 数据湖存储来说用户可以根据自己熟悉的协议对文件进行上传、下载等操作。它是个标准对象存储,也是文件存储,同时也是 HDFS,可以同时应用于三个生态,具体如图所示:
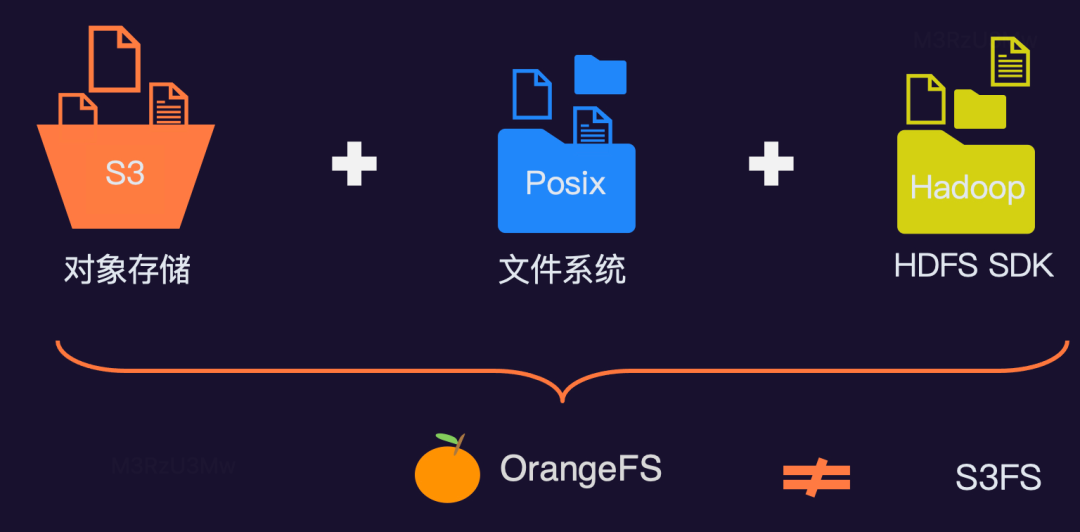
我们在 OrangeFS 封装 VFS 和 PathFS 层。VFS 提供给 Posix 协议使用,封装了文件所有操作接口,包括:打开、创建、读、写、同步等操作。PathFS 提供给 S3、HDFS 协议使用,主要是单文件多个操作集合,例如:上传文件,就是创建、写操作集合。无论是 VFS 还是 PathFS,那么读写,都会调用融合写和融合读接口,那么下面我们来看下融合读和融合写的流程设计。
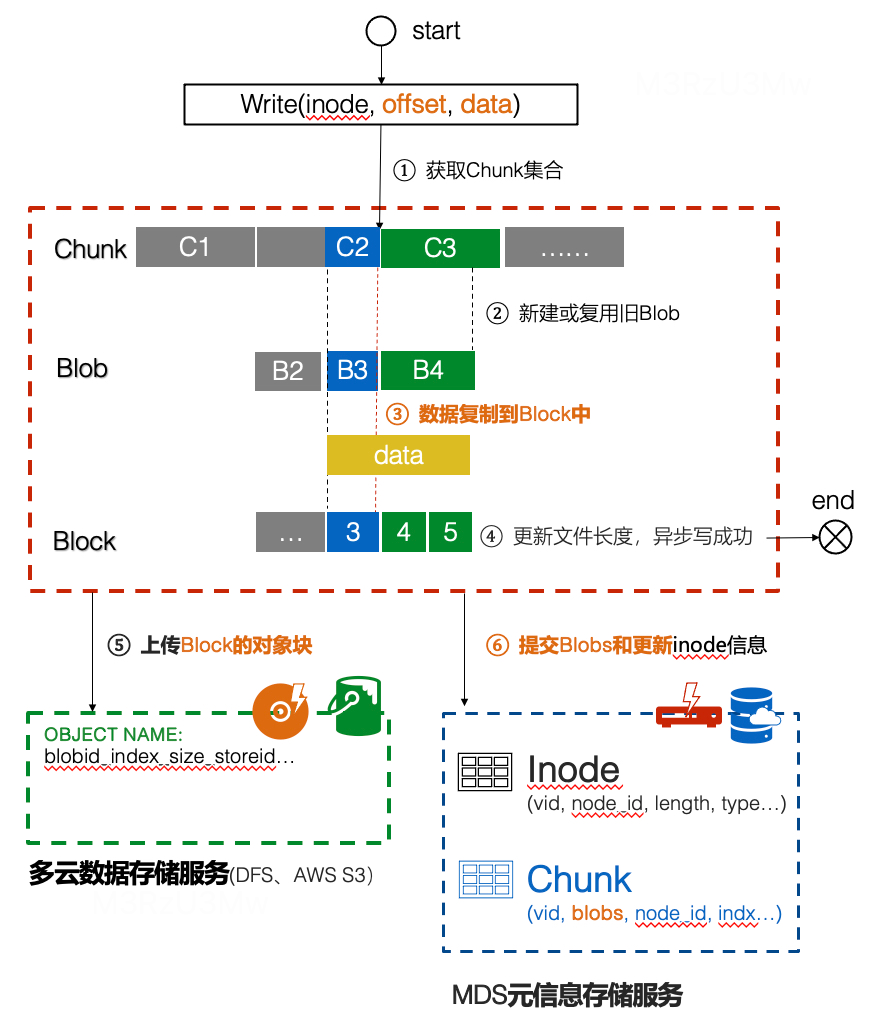
2.1 融合写流程
- 按 inode 找到对应文件上下文,然后通过 offset 和 data 长度获得 Chunk 固定逻辑块集合。
- 检查 Chunk 固定逻辑块是否有可复用的 Blob,如果存在,那么直接使用;如果不存在,那创建新的 Blob。
- 将 Blob 偏移 offset 和 data 内容拷贝到对应的 Block 对象存储块中。
- 数据信息拷贝完成后,更新元信息中的长度。异步写请求可以向 FUSE 返回写成功。
- 上传 Block 对象块到数据存储服务中。
- 提交 Blob 和更新 inode 长度/修复时间,也是版本号。
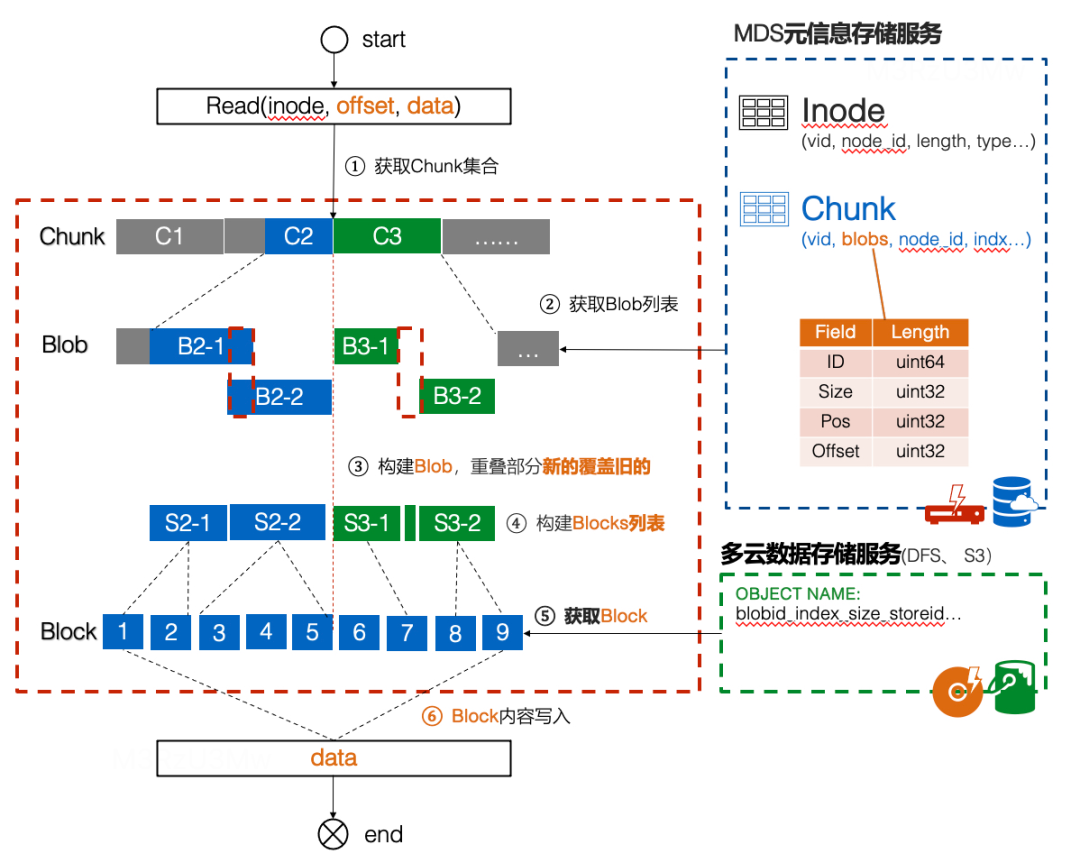
2.2 融合读流程
- 按 inode 找到对应文件上下文,然后根据 data 长度和 offset 获得 Chunk 固定逻辑块集合。
- 获取每个 Chunk 对应的获取 Blob 列表。优化从缓存中获取,如果之前没有缓存会从RDS中获取,并进行缓存。
- 构建每个 Chunk 对应的 Blob,重叠部分新的覆盖旧的。
- 根据每个 Chunk 对应的 Blob、offset 读取长度,构建对象存储块列表 Blocks 。
- 根据对象存储块列表 Blocks 去数据存储服务中获取每块 Block 内容。若开启缓存会优先查询本地缓存中的对象,存在则可读缓存信息,没有则需要向多云数据存储服务发送读请求。如果本地缓存空间足够,那么会缓存本次数据,并通过 LRU 淘汰缓存。
- 获取到的 Block 内容写入到 Data 中,所有的数据拷贝完成后,向 FUSE 返回读成功。
3. 云原生技术
为了能在 K8S 中使用 OrangeFS 数据湖存储,我们基于 fuse 的开发一套文件系统客户端,完全兼容 Posix 协议。为了适应不同的业务,我们提供两类网络盘:一类为数据盘,专门用于存储数据。另一类为日志盘,专门用于日志。网络盘和日志盘最大区别是日志盘支持弱化同步、黑洞、自动超时等特性,出现严重故障可自动降级,保证不卡业务主流程。
3.1 OFS-CSI插件
为了实现 csi node-driver 的无感升级,我们拆分了node-driver 的功能,将OFS-CSI 呈给super-agent托管,与 provisioner 和 kubelet 均采用宿主机 Unix Domain Socket 进行交互,有效地避免 node-driver 升级带来的现有挂载点失效。
3.2 OFS-Posix客户端
在大多数操作系统中,文件系统可以在内核态(Kernel Mode)和用户态(User Mode)两个不同的权限级别上运行。
内核态文件系统是操作系统核心的执行环境,具有更高、更广泛的访问权限,但也有安全风险高、开发和调试难度高等缺点,一旦出现一个错误的实现可能会导致系统崩溃或数据损坏。
用户态是普通应用程序运行的环境,性能比内核态稍差、权限受到限制。但它的优点是实现从内核态转移到用户态,允许开发人员在用户空间编写文件系统的逻辑而不需要修改操作系统内核。这样做的目的是为了简化文件系统的开发和调试过程,增加文件系统的灵活性,并减少由于文件系统错误导致整个系统崩溃的风险。著名的用户态文件系统实现包括 FUSE(Filesystem in Userspace)在 Linux上,MacFUSE 在 MacOS 上,以及 WinFsp 在 Windows 上。这些用户态文件系统实现为开发人员提供了在用户态运行自定义文件系统的接口和框架。
FUSE 的主要工作原理是通过内核模块(kernel module)和用户态库(userspace library)之间的通信,将文件系统的请求从内核传递到用户态进程,然后在用户态进程中处理这些请求,并将结果返回给内核。这种设计允许用户态进程处理文件系统操作,而无需直接访问内核数据结构或硬件设备。具体如下图所示:
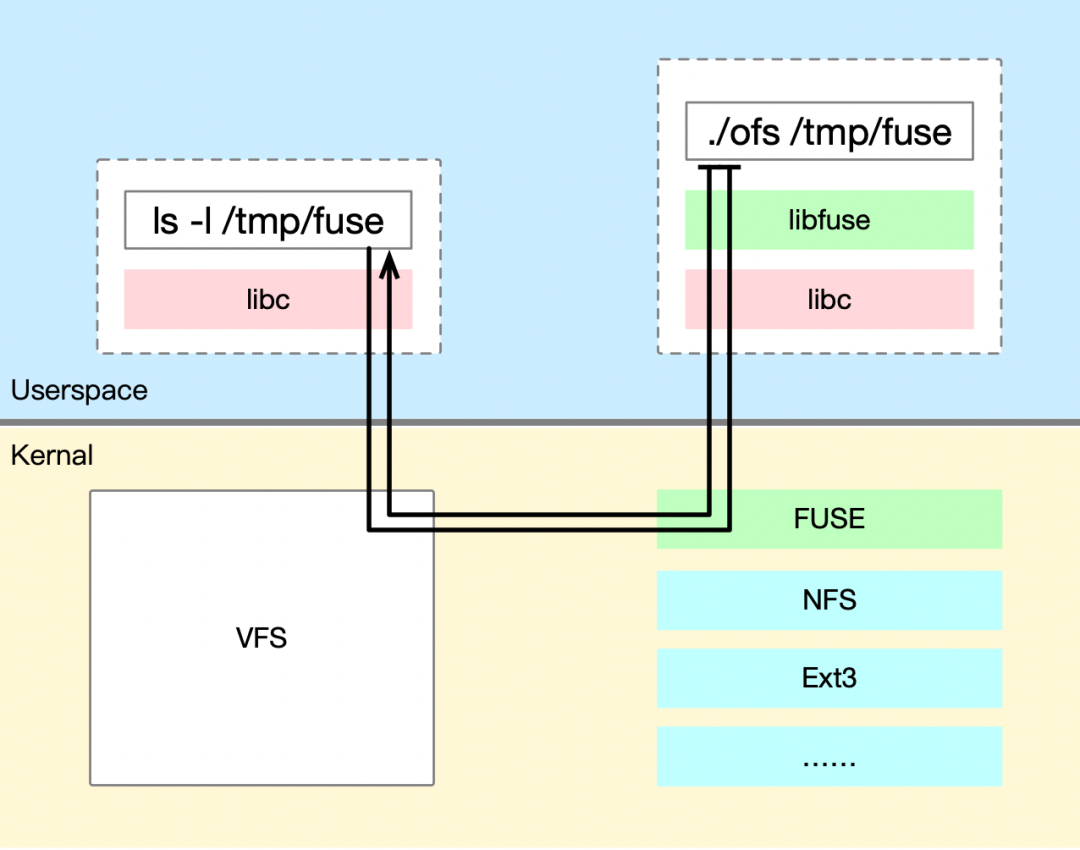
为了保证系统稳定性、降低安全风险和开发调试难度,OrangeFS 选择在用户态权限级别上运行,整个系统共有三部分组成:OrangeFS-Posix、MDS 元信息存储服务、多云数据分片存储服务。总体架构如下图所示:

OrangeFS Posix**:是基于 fuse 的文件系统客户端,完全兼容 Posix 协议。
- 接收与处理 FUSE 的操作请求,与 MDS Cluster 交互实现文件元信息的增删改查及管控操作, 与自建 IDC 的 DFS 数据存储系统或公有云 OSS/S3/COS 等系统交互实现文件分片数据的增删改查。
- 支持卷级的 QoS,包括:带宽、QPS、黑洞等能力。
- 支持元信息缓存和数据缓存以提高性能.
**3.2.1 超时机制
为了保证用户可用性,避免单个接口操作耗时长而夯主上层应用,但可能会有雪崩效应,例如:Read、Write、Flush、FSync、Fallocate 等重量级操作,我们支持超时机制。
启动 Goroutine 来做具体的 File OP 操作,Fuse 下发的主 IO 流程的 Goroutine 来接收 Interrupt、Timedout、Done 的信号。OFS内部所有的 Goroutine 使用G池来管理,重复利用G。
Interrupt信号返回 EINTER错误、Timedout 信号返回 EBUSY 错误。
3.2.2 黑洞机制
为了保证用户的可用性,容忍丢失少部分数据。Write 支持黑洞机制,如果开启了黑洞,在超时时间内没有写成功,那么直接返回OK。
对于日志场景,不允许夯住,但是可以少量丢失部分数据。如果开启了黑洞丢失了少量数据,那么丢失的数据在文件中的体现就是一块空洞。即用户可以根据文件空洞知道丢失了数据的 range。
主IO流程的G监听 Timedout 信号,如果在 Timedout 时间内没有处理完成,那么向 VFS 层返回成功,同时返回本应写入的字节数。
3.2.3 弱化Sync
大量小写可以延迟写入后端 S3 或 DFS 存储引擎,OFS 可以合并大量的小写,降低元数据量和避免后端 S3 或 DFS 存储引擎过多小文件。
OFS 支持弱化 Sync,在单个客户端读写的场景,开启了弱化 Sync,那么用户主动调用的 Flush、FSync 都会不起作用,依赖 OFS 自身每隔一段时间的 flush 机制来做 sync。
简单应用
我们实现的多协议融合,也就是分布式文件系统挂载卷的根目录,同时也是 S3 或 HDFS 根目录,具体的 OFS 多协议融合的应用如下:
- 我们在容器或 Linux 下挂盘并查看列表。
/home/ofs/bin/orangefs posix mount -debug=true -log-dir=/home/ofs/log -rs-addr=10.0.0.1:8030 -rs-model=mds -volume-name=ofs2 -mount-point=/home/ofs/mount

- 通过 S3 协议下载数据。
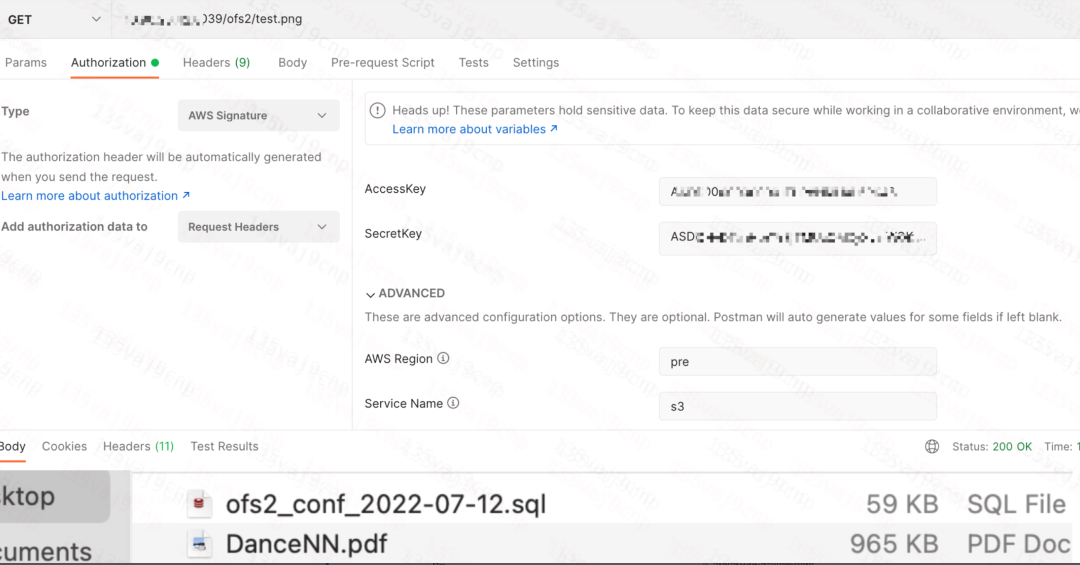
- 通过 S3 协议上传数据。
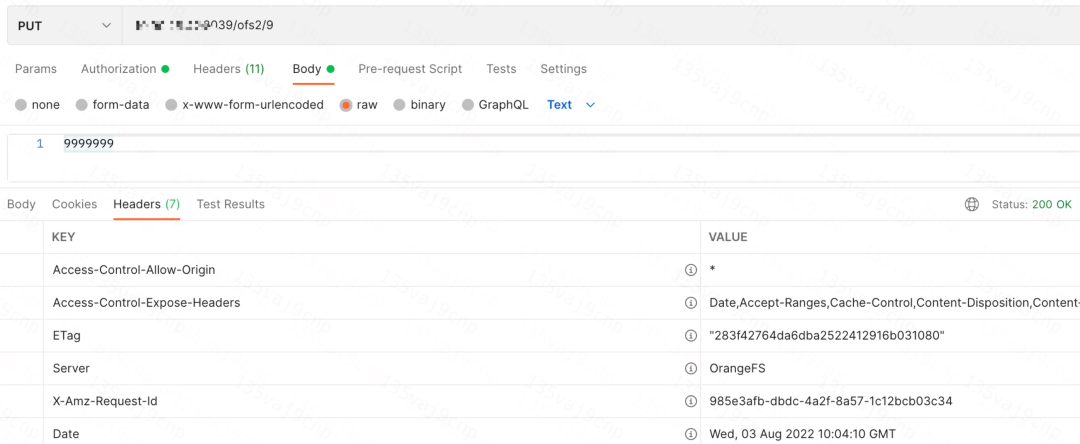
- 通过 Posix 协议挂盘查询文件及数据。
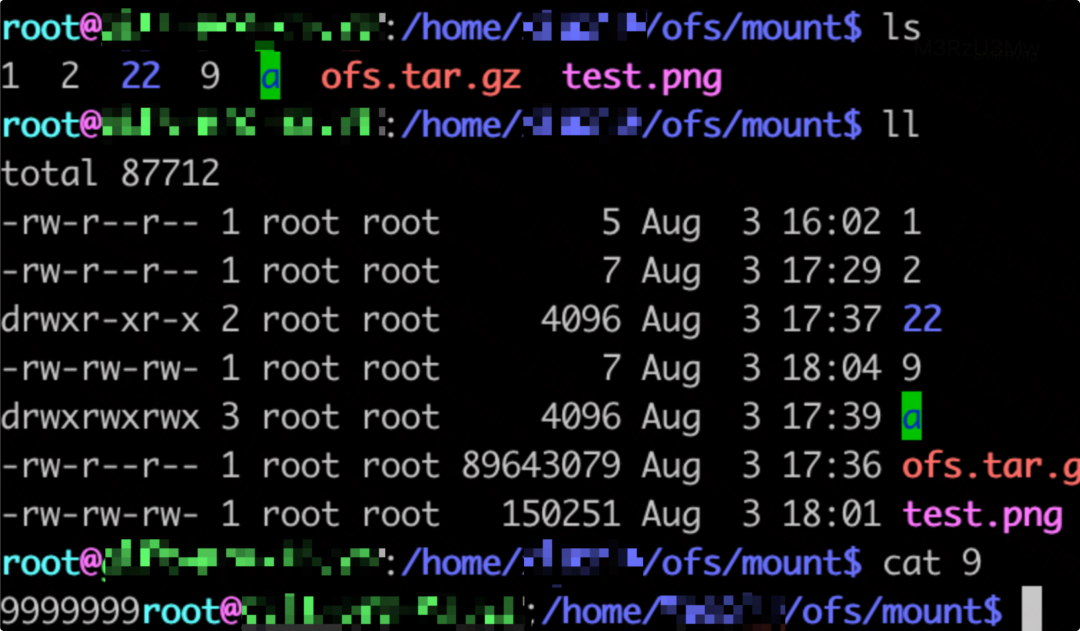
- 通过 HDFS 协议访问数据。
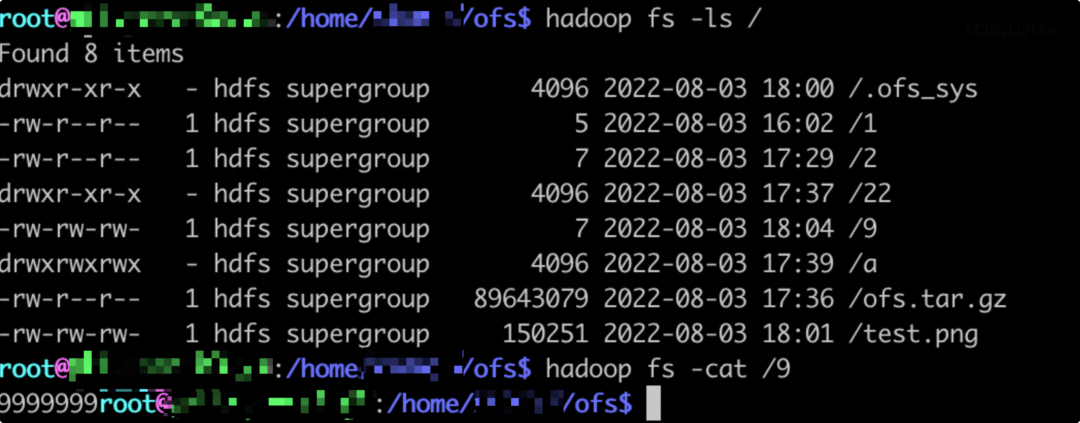
本文总结
本文介绍了滴滴为什么要开发数据湖存储的原因,解决方案思路、核心几个技术设计以及简单应用。整个存储已接入上百PB在线实时业务,其中 OrangeFS 产品,已成功应用于网约车日志、机器学习、金融、效能、服务发现、大数据等场景,总容量已超过十几PB。
后继我们会陆续推出针对数据湖存储元服务、多云数据存储、Posix 热升级等技术点文章,欢迎大家与我们交流。


