我们是如何做数据稳定性保障的? - 滴滴技术
滴滴客服业务属于强运营的业务,运营的核心抓手是指标数据。这些指标有的是为了达成战略目标的OKR指标,有的是为了达成与合作伙伴结算的结算指标,做好数据稳定性,对整个客服业务的运营来说至关重要。
解读数据故障治理建设目标
实时类指标,包括进线量、排队量、接起率、触达率等指标。滞后类指标,包括解决率、关单率、升级率、满意度、服务质量等指标。
过去两年,为了保障业务的连续性,我们投入了比较多的精力在稳定性建设上。整体建设分为三个阶段:
第一阶段:
以故障为中心的稳定性建设,围绕系统故障的事前、事中、事后系统性落地了一系列的工程能力、流程机制、建设方法论;围绕降发生、降影响,最终故障数和故障时长大大降低。
第二阶段:
以业务为中心的稳定性建设,围绕业务特点,从业务的实际情况出发,成立横向跨组织专项团队,解决业务与技术衔接部分存在的稳定性问题,实现技术对于业务连续性保障的全局最优。
第三阶段:
常态化能力建设,随着稳定性建设工作的不断深入,组织上对于稳定性团队工作的要求越来越多,已经从单纯的围绕技术稳定性的工作,升级到了覆盖安全合规、降本增效等相关工作内容。为了避免运动式的工作投入,让稳定性工作实现低成本、可持续,会围绕完善自动化工具提效,建设可持续的运营机制,最终塑造团队的稳定性工作文化。
我们去年完成了系统稳定性建设的第一阶段工作,形成了对于实时类指标的保障。数据稳定性建设属于第二阶段的工作,它的工作内容和业务特点强相关,主要解决业务滞后类指标的生产和使用过程中的稳定性问题。**系统稳定是数据稳定性的基础,只有做好了系统稳定性,才有实现数据稳定性的基础。
为了做好数据稳定性建设,我们先做了以下几件事。
制定数据故障定级标准,做数据分级
我们有1000+指标,由于资源有限,不可能面面俱到,制定数据故障定级标准,其实是回答了我们要保什么样的数据,以及保到什么程度。清晰的定义了什么样的影响是故障、什么样的故障影响对应什么级别、什么样的指标对稳定性要求更高。
经过这一步,我们明确了数据分级需要保的指标类型包括:OKR指标、结算指标、其他指标。其中OKR指标涵盖了工作效率维度、服务质量维度、安全维度和风险维度。
目标拆解
有了数据指标定级标准后,我们就需要考虑如何做好数据稳定性保障这件事了。
稳定性建设工作需要三方共建(研发、数仓、数据),三方共同服务业务,需要彼此分摊一定的故障比例,将稳定性目标拆解到三方头上,让大家劲往一处使。
明确打法
目标拆解之后,需要明确相关打法和节奏,包括完成目标的具体原则、计划和动作。具体计划涵盖事前、事中、事后环节,目标是降低故障数和降低故障级别。相应的方法论是围绕:目标体系、人员意识、人员素质和系统工具。

很多技术同学对做系统稳定性有比较多得了解,但数据稳定性建设在原则上还是有非常多的不同的,简单介绍几条。
数据故障最看重什么?
先说答案,是时间。影响时间有两点:数据影响总量和数据修复时长。
区别于系统可用性故障,数据故障最看重的是数据回溯修复的时间。就是如何快速将影响的数据恢复、回溯回来,在数据被使用之前完成数据的恢复。
这就需要在事前、事中、事后提供一些保障:
- 事前保障:研发在操作数据或做库表变更之前,知晓是否会影响相关ODS和关键指标,进行合理评估后,就可以避免造成可能的数据指标伤害。
- 事中保障:围绕关键库表字段,进行报警完善和精细纬度。在出现问题时,可以最快发现问题、定位问题、并快速介入解决问题。发现得早,影响的数据量少,修复过程会非常快。
- 事后保障:有趁手的修复工具,或沉淀了可复用的冗余数据和修复脚本,帮助做数据回溯,整体的故障数据回溯效率将会大大提高,进一步降低数据类故障的影响和降低故障级别。
所以围绕以上保障原则,前期工作重点投入在事前(三方协作SOP、专项checklist自动化机制)、事中(核心库表、字段的监控报警覆盖)、事后(数据冗余预案、快速修数模板)上来,就是预防为主+提升回溯效率。
数据故障定级标准 这部分目前比较复杂,很多同学提的问题大多也出现在这里,虽说很多人知道制定故障定级标准很重要,但制定一个简单、可理解、可执行的标准其实很难。
首先要做的是数据分级,这样才可以对不同等级的数据提供不同程度的资源保障。
指标划分为三类:OKR指标、结算类指标、普通指标。三类指标对于数据错误敏感度不一样,OKR指标如果卡在一个阈值点是影响比较大的,会影响OKR的达成。结算类主要涉及到给供应商的结算。
影响故障级别因素:主要是时间,从发现问题到问题修复的时长。
事故影响天数计算因为数仓侧独有的特点,数据按时间分区,比如某天数据只被影响了一个小的时段,也需要重新制作这一整天分区数据回溯,但发现得越早回溯的分区数据也就越少,效率还是有保障。
指标与ODS表之间的关系这部分是研发同学参与程度最高,降低数据故障级别最重要的一个抓手。
整个指标体系有1k+指标,通过数据血缘分析,还是可以找到需要聚焦的数据库表、字段进行保护的。基于指标血缘关系,找到核心库表-ODS表的映射文档。
研发侧重心在于保障ODS表之前数据生产链路的稳定可靠,数仓同学关注数据使用链路的稳定可靠,以及进一步缩短ODS数据回溯的时间。
挖掘数据故障现状
上面介绍的是数据稳定性建设的一些原则性的内容,具体工作还是需要回到现状上看具体问题。和数仓、数据同学对历史故障进行了盘点,以下几个问题比较明显:
- 研发缺少对指标、ODS的关注与理解
- 指标及ODS表缺少责任人
- 研发、数仓、数据三方缺少有效的协作机制
- 关键指标的报警不够精细,覆盖度不够
- 故障处理过程缺少SOP指导,导致出现修错数、返工的情况
- 缺少趁手的快速回溯数据工具
研发缺少对指标、ODS的关注与理解过去研发同学对数据的关注主要停留在数据库层面,关于数据落库之后数据怎么用、生成什么样的指标,是没有关注的。 更多的关注点在于指标的生产,对于指标生成的前置链路缺少了解,很多指标生成规则的制定只是“一面之词”。
结合研发、数仓、数据产品三个角色可以拆出数据生产流程如下:
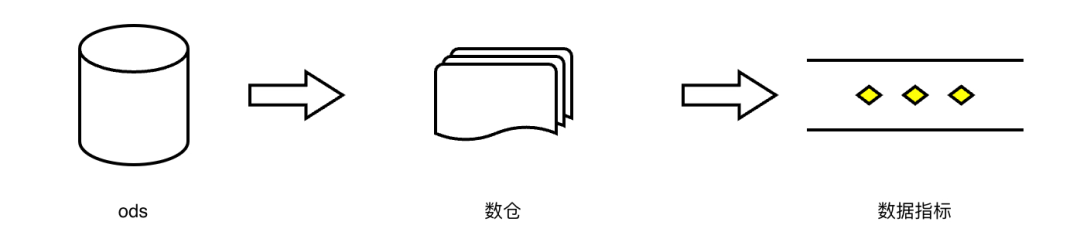
- 研发侧:主要关注ODS对应的核心库表数据生成链路的可靠性,保障数据准确,对其承担责任;
- 数仓侧:主要关注ODS数据异常时的回溯,确保数据指标生产的可靠,对其承担责任;
- 数据侧:主要关注指标生成是否准确,对其承担责任。
在有限的人力资源下,前期集中资源重保关键指标,如OKR类、结算类、风险类指标。在原有系统稳定性的监控报警基础之上,丰富数据指标维度的监控报警。
指标及ODS表缺少责任人在确定了研发要对核心库表及ODS承担责任之后,就可以圈定具体的人对ODS的认领,划清责任人。一旦数据生产或使用链路发现指标有问题,就可以通过ODS血缘快速找到对应的负责人,并进行跟进。
过去很多数据故障发生后,想要找到对应的研发owner,可能就需要2个月时间。现在责任到人,发现问题之后,当天就可以找到研发owner,并产出修复方案了。所以责任到人这事,看起来简单,但收益巨大。
对系统owner来说,工程上不仅需要考虑系统稳定性的设计,还要关注对应的几个核心库表、字段的稳定性设计。
为进一步提升关键指标监控的覆盖度,降低系统owner的关注成本,平台提供一套核心ODS指标采集和监控的自动化工具,实现早发现早介入。
研发、数仓、数据三方**缺少有效的协作机制** 研发、数仓、数据隶属不同团队,之前协作并不紧密,某种程度导致了数据故障处理时间的变长。共建之后,明确了三方的协作机制,三方关键责任人在同一个群中,将关键信息沉淀在群公告中。研发变更或数据指标变更,通过内部沟通软件的机器人,实现自动化通知、协作。
关键指标的报警不够精细 研发之前配置的监控报警,还只是围绕系统可用性指标配置的,没有覆盖库表、字段数据准确性的监控维度。
数仓及数据侧之前的监控报警,要么不准,要么太滞后(T+N,N可能是30天)。如果问题发现太晚了,数据回溯成本会变高,需要提升对数仓及数据侧监控报警的巡检,尽量做到T+1,尽快发现问题并快速处理问题。
系统owner需要对于关键库表、字段也进行埋点监控,当数据不对、不准、丢失的时候,触发报警。
可以增加的报警规则包括但不限于:
- 字段非空校验
- 字段类型变更
- DDL增删字段变更
- 关键表指标的同环比变化
- 时间类型的格式确认(时间戳 or yyyy-MM-dd)
- 跨系统RPC数据一致性比对
- 历史数据对账,同环比
- 字段内容的规则有变化,正则匹配
通过BCP+低代码平台,系统owner录入库表字段规则,基于binlog监听,异常时触发报警。
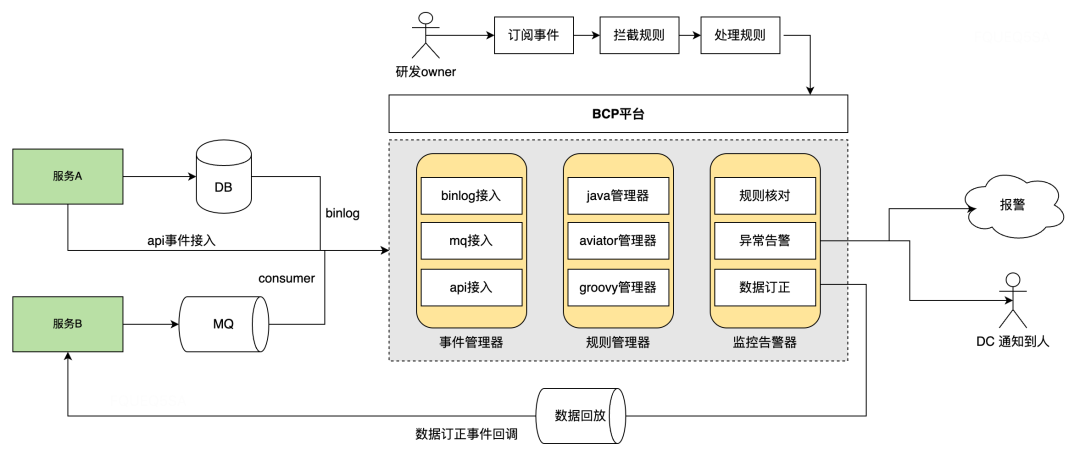
关键指标对账、及时发现,通过类TCC接口实现数据的快速订正。大原则来说宁可误报,也不漏报,同样的要求,也适用于数仓及数据侧系统。
故障处理过程缺少SOP指导,导致修错、返工情况有时一个ODS字段出现问题,可能会影响到多个指标,但有的是ODS指标,有的是普通指标。
先修复哪个指标可能会影响最终故障的定级,或者故障修复前没有得到准确的信息,造成了二次伤害。
建立故障处理协作的SOP,结合内部沟通软件机器人,涵盖事中及事后的操作指导,减少修错数、返工情况的发生。
一旦指标生成链路发生变化(研发的DDL类操作、数据侧的指标级别升级),需通知相关干系人。
梳理标准的故障应急标准和流程,明确各阶段职责和相关干系人。
缺少趁手的快速回溯数据工具建设一些数据可靠性保障的工具,提高一些三不管环节的效率保障。通过工具完善解决靠人力或现有回溯工具能力不足问题。
数据采集链路加固:包括改造原有通过public.log日志文件数据上报方案,加固数据总线(logbook)确保数据的不丢、不重、可回溯。
数据回放提升修数效率:建设核心链路数据回放能力,当发现链路中存在数据丢失的情况,通过数据回放,快速修正异常数据,提高修数效率。
可复用修数脚本,防止修错数情况发生:沉淀一些高频场景下修数模板和脚本,修复环节可通过替换模板的方式,复用相关修数脚本,降低修错的风险,提高修数效率。
以上流程、规范、标准,借助工具自动化手段提效和保障准确性。
建设方案与路径
事前、事中、事后原则
总结来说,对于数据类型故障,事前、事中、事后的主要动作如下:
- 事前:明确哪些指标是关键指标,明确哪些ODS表和关键指标关联,明确相关ODS表的负责人,明确全链路多环节的协作SOP,把不确定性的情况变成确定性的共识;
- 事中:做好精细化监控报警覆盖。很多数据指标是T+N形式产出的,在监控报警配置上存在惯性,在数据决定用的时候才报警,此时故障影响已产生,当前原则是“宁可误报也不漏报”,让最靠近ODS库表的系统做好监控,要做细做实,不能抱侥幸心理,定期巡检;
- 事后:对于数据类故障来说,最重要的是快速修数,之前出现过很多“止损5分钟,修数两礼拜”的情况,所以有趁手的工具就非常重要。在这个角度从“盘、优、建”三个层面入手,“盘点”现有数据生产和数据加工链路上工具的完善情况;“优化”现有工具,使其进一步好用、易用;“建设”缺失的工具,降低人工介入程度,缩短数据恢复链路,自动化提效。
持续运营明确数据及指标变更的双向通知:
- 数据指标变化时通知到研发
- 研发做数据变更,如操作DDL时通知到数据
- 新OKR类指标产生,以邮件形式通知
建立围绕核心指标梳理的指标——ODS映射文档,文档中涉及到的关键库表字段修改时,如数据修改、字段下线,操作前都需要在群中做同步周知,并@相关的数据同学周知。
如未通知,后续在复盘时将追责操作流程标准上的问题,工具层面以内部IM工具机器人做兜底。
建立奖惩机制,在规章制度未遵守的情况下进行惩罚,对于遵守标准流程的good case的个人予以奖励,通过奖惩机制+周期review的方式,实现数据稳定性建设的文化塑造。
建设效果
在产研、数仓、数据、业务多方共同努力下,通过及时发现问题、完整的问题排查、定级标准、故障复盘机制、自动化工具和运营工作的深入,今年数据故障数量及数据故障处理时长均有了明显的降低。
- 故障数量较上年减少了42%
- 故障修复时效较上年提升了134%
除了指标上看到的明显收益,也存在一些隐性收益。
通过完整的机制建设,明确了三方职责边界,规范了判责、透传、分摊等问题,提高了沟通效率、提升数仓同学的幸福感。
明确了一个典型故障的处理流程,覆盖了关键环节和关键责任人,为后续的进一步文化塑造和自动化提效,提供了很好的基础。
总结
之前研发同学的故障处理世界观是基于系统稳定性保障构建起来的,大家习惯快速止损,这样可以避免一个小故障变成一个大故障。但这个世界观在数据故障处理上可能不是那么奏效。
数据故障有其特殊性,相对于系统稳定性来说,最简单的一个差别在于,数据故障发生之后的止损动作,只是整个数据故障恢复处理的开始:止损5分钟,修复两礼拜。
数据稳定性建设世界观的第二部分,是要留有冗余,不管是用于事后数据修复的数据冗余,还是故障发生之后的修复脚本的复用,都属于冗余的一部分。
数据稳定性的预案应该是快速、准确的,且降低二次伤害的可能,也就要求我们预案脚本要准确可靠,定时review。
故障发生后的数据回溯修复处理才是真正的工作大头,这个阶段工作量大,而且琐碎,是大量的体力活,让大家苦不堪言,标准化流程+自动化手段可以提升幸福感。
本着“平时多流汗,战时少流血”的原则,有四个要求:
- 事前多投入:如果识别到某个需求或者技术变更动作,可能对关键数据指标产生影响,那尽量在操作之前就找相关干系人进行充分评估,不要嫌麻烦,不抱侥幸心理。
- 有全局视角:有时数据同学决定一个指标的生成规则时,视角很局限,看到一个表有对应的值就使用了,殊不知这个值是不靠谱的。用了既得不到保障、也引入了不必要的技术债务,对后续业务系统的持续迭代形成了掣肘。好的方式是和研发同学坐在一起好好聊聊,站在全局视角看看这个指标在哪里生成最合适。
- 方案落实到位:各种稳定性要求,比如监控、报警机制要落实到位,需要以编码的方式固化到自己的系统链路上。通过复盘发现,很多故障是执行到位就可以避免的,比如字段必须有值、必须符合某种数据类型、必须属于某个范围内的字段,这些可以非常简单的以编码方式落实在代码里。很多时候故障的重复发生,就是因为执行不到位。
- 悲观者正确:大家听过“乐观者成功、悲观者正确”,稳定性就是要守底线。在方案设计时,有“悲观者”的态度多思考不是坏事,做好防御式编程,达成目的才是好事。