
探索跨端开发的常用解决方案:条件编译的实现 - 阿里技术

( 本文阅读时间:15分钟 )
01
前言
跨端开发是指在不同的平台或设备上开发同一种软件应用,例如:一个应用程序可以同时运行在移动设备、桌面电脑和浏览器等不同的设备上,或是一个小程序能够在微信、支付宝、抖音等多个平台使用。跨端开发的优点在于可以节省研发和维护成本,让开发者者编写一套符合规范的代码,由编译器将其编译生成出可以发布在每个平台的产物,在更广泛地覆盖用户群体的同时,可以保持产品在不同渠道的一致性,减少用户的上手使用成本。
然而,由于不同平台存在一些无法抹平的特性差异,或是针对特定平台可能会有不同的产品需求,比较常见的做法有以下两种:1. 在代码中编写大量的if、else 来处理不同平台或需求的差异;
- 对编译后的产物进行二次开发,或维护两套差异性代码。
以上方式虽然一定程度上可以满足跨端开发的需求,但是也带来了大量问题:
- 性能下降:产物中充斥着大量其他平台的代码,造成代码执行性能底下,增大产物体积,在小程序这种有产物体积大小限制的项目中并不适用;
- 难以维护:业务上仍然需要维护多套代码,让后续的迭代和升级变得混乱,降低研发效率;
- 违背初心:跨端开发的目标是「一次编写,多处运行」,以上方案让跨端研发一定程度上失去了转换的优势。
因此,最好的方式就是能够根据不同目标平台,打包只与该平台相关的代码产物,无其他冗余代码,产物体积小,利于后续的维护,而这个描述就很容易让人想到条件编译,本文就探索一下条件编译的实现原理。
02
现状
Conditional compilation is a compilation technique which results in an executable program that is able to be altered by changing specified parameters. In C and some languages with a similar syntax, This technique is commonly used when these alterations to the program are needed to run it on different platforms, or with different versions of required libraries or hardware. —— From Wikipedia「Conditional compilation」
大意是:条件编译是一种编译技术,它可以通过更改指定参数来更改的可执行程序,在类似 C 语言中,出于对程序代码优化的考虑,希望只对其中一部分内容进行编译,此时就需要在程序中加上条件,让编译器只对满足条件的代码进行编译,将不满足条件的代码舍弃,这就是条件编译。—— 维基百科《条件编译》
条件编译常用的写法基本是以#ifdef 标识符或#ifndef 标识符作为开头,以#endif结尾,中间编写符合当前标识渠道的代码段。
#ifdef 标识符
仅在某平台存在的代码段
#endif
#ifndef 标识符
除某平台外,其他平台均存在的代码段
#endif
不同框架/编译器对标识符的取值都有自己的一套规定,不同的值对应的生效条件不同,例如 Uni-app 的可选值有 19 项,覆盖了微信小程序、支付宝小程序、快应用、App、H5 等场景,Taro 的可选值共有 8 项,包含微信小程序、支付宝小程序、抖音小程序、H5 等场景,MorJS 相对独特一些,其标识符分为两类:1. 默认注入的变量:各编译目标平台(微信小程序、支付宝小程序、百度小程序、抖音小程序、Web 应用),编译配置名,是否是生产环境等;
- 自定义条件编译变量:MorJS 支持在配置文件中自定义条件编译的变量值,并提供了如下的语法:
#if 标识符
符合变量值判断条件的代码段
#endif
- 文件维度的条件编译:除了使用代码中的特殊的注释作为标记,实现条件编译外,MorJS 提供基于特殊规则的文件后缀,实现文件维度的条件编译。
例如:在同一目录下的index.js、index.wx.js、index.tt.js文件,在编译微信小程序时会使用优先级最高的index.wx.js文件,在编译抖音小程序时则会使用index.tt.js文件。
开发者也可以在配置文件中,添加配置conditionalCompile.fileExt来自定义文件维度条件编译的后缀值,以配置{ fileExt: [‘.my’, ‘.share’] } 为例,编译时将按优先级查找index.my.js>index.share.js=>index.js 文件用于编译构建。
03
实现
3.1 代码维度条件编译
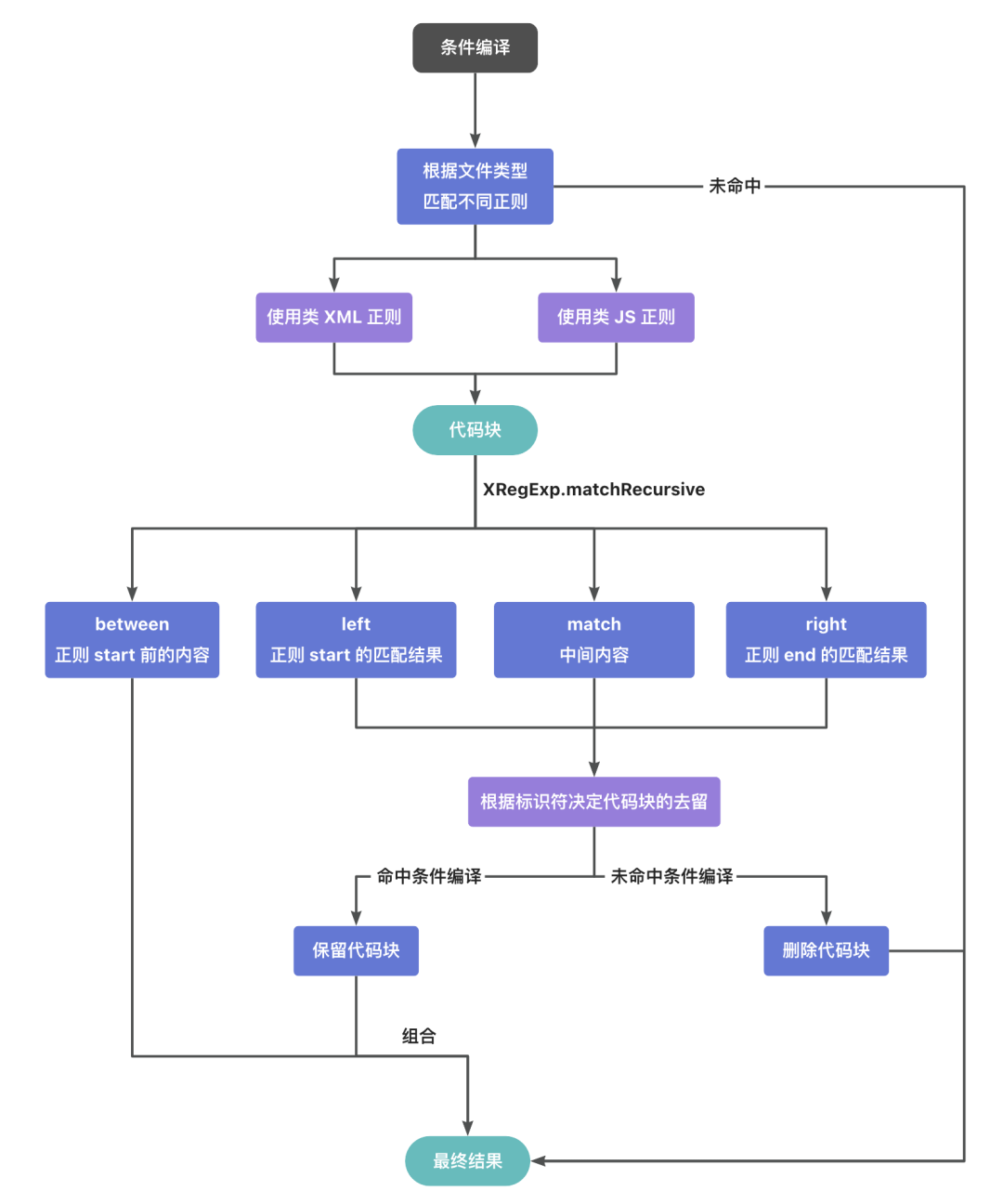
根据文件类型匹配不同正则
export function preprocess(
sourceCode: string,
context: Record,
ext: string,
filePath?: string
): string {
let type: string
if (JsLikeFileExts.includes(ext as JsLikeFileExtType)) {
type = 'js'
} else if (XmlLikeFileExts.includes(ext as XmlLikeFileExtType)) {
type = 'xml'
}
if (!type) return sourceCode
return preprocessor(
sourceCode,
context,
{ type: RegexRules[type], srcEol: getEolType(sourceCode) },
undefined,
filePath
)
}
<span>pr</span>eproce<span>ss</span>方法针对文件后缀(入参<span>ext</span>)进行区分以匹配后续注释的正则规则:
1.<span>JsLikeFileExts</span>:命中 Style 文件,Config 文件,Script 文件,Sjs 文件等
- Style 文件
<span>.wxss</span>、<span>.acss</span>等,预处理器<span>.less</span>、<span>.scss</span>、<span>.sass</span> - Config 文件:
<span>.jsonc</span>、<span>.json5</span>(<span>.json</span>文件无法编写注释) - Script 文件:
<span>.js</span>、<span>.mjs</span>、<span>.ts</span>、<span>.mts</span> - Sjs 文件等:
<span>.sjs</span>、<span>.jsx</span>、<span>.tsx</span>
2.<span>XmlLikeFileExts</span>:命中各端小程序 XML 文件,如<span>.wxml</span>、<span>.axml</span>等。条件编译的正则也同样分为两类,命中<span>XmlLikeFileExts</span>规则的使用 xml 正则,命中<span>JsLikeFileExt<span>s</span></span>规则的使用 js 正则。
const RegexRules = {
xml: {
if: {
start:
'[ t]*|!>)(?:[ t]*n+)?',
end: '[ t]*|!>)(?:[ t]*n)?'
}
},
js: {
if: {
start:
'[ t]*(?://|/*)[ t]*#(ifndef|ifdef|if)[ t]+([^n*]*)(?:*(?:*|/))?(?:[ t]*n+)?',
end: '[ t]*(?://|/*)[ t]*#endif[ t]*(?:*(?:*|/))?(?:[ t]*n)?'
}
}
}
以下是<span>XmlLikeFileExts</span> 文件类型的 if start 正则的可视化图:

3.2 调用 XRegExp.matchRecursive 将代码块拆分
<span>preprocessor</span>创建了一个回调函数<span>processor</span>,并调用 <span>replaceRecursive</span>使用<span>xregexp</span>库的<span>XRegExp.matchRecursive()</span>,该方法接受需要搜索的字符串和左右分隔符的正则,返回左右分隔符之间匹配到的字符串数组<span>matches</span>,而<span>matches.name</span>有四种情况:
<span>between</span>:正则<span>start</span>前的内容,直接作为字符串拼接<span>left</span>:正则<span>start</span>的匹配结果,执行<span>exec</span>方法并保存为<span>matchGroup.left</span><span>match</span>:处于正则<span>start</span>和<span>end</span>中间的内容,保存为<span>matchGroup.match</span>-
<span>right</span>:正则<span>end</span>的匹配结果,执行<span>exec</span>方法并保存为<span>matchGroup.end</span>,并调用回调函数<span>processor</span>获得处理后的字符串,拼接到前面
<span>between</span>的字符串后面:
function replaceRecursive(
rv: string,
rule: PreprocessRule,
processor: PreprocessProcessor
): string {
if (!rule.start || !rule.end) {
throw new Error('Recursive rule must have start and end.')
}
const startRegex = new RegExp(rule.start, 'mi')
const endRegex = new RegExp(rule.end, 'mi')
function matchReplacePass(content: string): string {
const matches = XRegExp.matchRecursive(
content,
rule.start,
rule.end,
'gmi',
{
valueNames: ['between', 'left', 'match', 'right']
}
)
// 如果未命中则直接返回内容
if (matches.length === 0) return content
const matchGroup = {
left: null,
match: null,
right: null
} as {
left: null | RegExpExecArray
match: null | string
right: null | RegExpExecArray
}
return matches.reduce(function (builder, match) {
switch (match.name) {
case 'between':
builder += match.value
break
case 'left':
matchGroup.left = startRegex.exec(match.value)
break
case 'match':
matchGroup.match = match.value
break
case 'right':
matchGroup.right = endRegex.exec(match.value)
builder += processor(
matchGroup.left,
matchGroup.right,
matchGroup.match,
matchReplacePass
)
break
}
return builder
}, '')
}
return matchReplacePass(rv)
}
3.4 根据标识符决定代码块的去留
目前距离完成代码维度条件编译只差最后一步,将获取到的这段条件编译包裹的代码块,通过<span>processor</span>回调函数来决定保留或是删除,核心是调用<span>getDeepPropFromObj</span>判断条件编译的项中,是否有符合标识符结果的项:
- 命中条件编译:递归执行
<span>replaceRecursive</span>中的<span>matchReplacePass</span>方法,使用<span>XRegExp.matchRecursive</span>二次检查是否仍包含条件编译的分隔符,未检测到则直接返回内容,完成保留代码块的过程; - 未命中条件编译:直接返回空,即删除代码块的过程。
const processor: PreprocessProcessor = (
startMatches,
endMatches,
include,
recurse
) => {
if (!startMatches || !endMatches || !include) return ''
const variant = startMatches[1]
const test = (startMatches[2] || '').trim()
switch (variant) {
case 'if': {
let testResult = testPasses(test, context) as any
// 当前传入的 context 没有该 key
if (testResult instanceof ReferenceError) {
logger.warn(
'当前条件编译中找不到变量,将按照条件执行结果为 false 处理n' +
`条件判断语句: ${test}n` +
`报错信息: ${testResult.message}` +
(filePath ? `n文件路径: ${filePath}` : '')
)
}
if (typeof testResult !== 'boolean') testResult = false
return testResult ? recurse(include) : ''
}
case 'ifdef':
return typeof getDeepPropFromObj(context, test) !== 'undefined'
? recurse(include)
: ''
case 'ifndef':
return typeof getDeepPropFromObj(context, test) === 'undefined'
? recurse(include)
: ''
default:
throw new Error('Unknown if variant ' + variant + '.')
}
}
3.5 文件维度条件编译
代码参考:https://github.com/eleme/morjs/blob/main/packages/plugin-compiler/src/entries/index.ts
文件维度的条件编译,核心是在编译过程中,构建文件依赖树及分组关系时,基于后缀的优先级顺序,添加对应端命中的文件,也就是配置文件中的<span>fileExt</span>的值,与需要查找的文件后缀进行拼接,返回查找到的第一个命中的文件地址。
async tryReachFileByExts(
fileName: string,
fileExts: string[],
contexts: string[],
parentPath?: string,
rootDirs?: string[]
): Promise {
// 确保无后缀
const fileNameWithoutExt = pathWithoutExtname(fileName)
const roots = rootDirs?.length ? rootDirs : this.srcPaths
const contextDirs = this.expandContextsAccordingToRootDirs(contexts, roots)
// 需要判断文件是否为绝对路径
const isAbsolute = path.isAbsolute(fileName)
// 支持多 context 返回查找到的第一个文件
for await (const contextDir of contextDirs) {
let filePath = fileNameWithoutExt
if (isAbsolute) {
// 绝对路径需要限制在 contextDir 之内
filePath = filePath.startsWith(contextDir)
? filePath
: path.join(contextDir, filePath)
} else {
filePath = path.resolve(contextDir, filePath)
}
for await (const ext of fileExts) {
// 拼接后缀
const finalPath = filePath + ext
if (await this.fs.fileExists(finalPath)) {
return finalPath
}
}
}
}
值得一提的是,为了支持不同类型的文件编译,及各端默认的特殊后缀文件,MorJS 实现了一套文件优先级的计算方案,最终编译时如遇到同名文件,将使用优先级数值更高的文件进行编译:
- 配置了自定义入口文件 customEntries 的固定值为 1000,优先级最高;
- 条件编译文件基础值为 20,配置多个条件编译后缀时,位置越靠前的后缀优先级越高,步进为 5;
- native 文件固定值为 15;
- 微信 DSL 文件固定值为 10,如 wxss 或 wxml 或 wxs 文件;
- 支付宝 DSL 文件固定值为 5,如 acss 或 axml 或 sjs 文件;
- 普通文件固定值为 0,如 js 或 ts 或 json 文件。
enum EntryPriority {
CustomEntry = 1000,
Conditional = 20,
Native = 15,
Wechat = 10,
Alipay = 5,
Normal = 0
}
function calculateEntryPriority(
extname: string,
isConditionalFile: boolean,
priorityAmplifier: number = 0,
entryType: EntryType
): EntryPriority {
if (entryType === EntryType.custom) {
return EntryPriority.CustomEntry
}
if (isConditionalFile) {
// 按照优先级自动放大
return EntryPriority.Conditional + 5 * priorityAmplifier
}
if (
this.targetFileTypes.template === extname ||
this.targetFileTypes.style === extname
) {
return EntryPriority.Native
}
if (
this.wechatFileTypes.template === extname ||
this.wechatFileTypes.style === extname ||
this.targetFileTypes.sjs === extname
) {
return EntryPriority.Wechat
}
if (
this.alipayFileTypes.template === extname ||
this.alipayFileTypes.style === extname ||
this.alipayFileTypes.sjs === extname
) {
return EntryPriority.Alipay
}
return EntryPriority.Normal
}
04
效果
4.1 代码维度
wxml/axml 文件类型
<span>#ifdef</span>用于判断是否有该变量,以下代码仅在微信和支付宝端会显示对应的内容,在其他端则无显示:
只会在微信上显示
只会在支付宝上显示
acss/less 文件类型
<span>#ifndef</span>用于判断是否无该变量,以下代码的效果为:除微信外的其他端显示红色背景色:
.index-page {
/* #ifndef wechat */
background: red;
/* #endif */
}
js/ts 文件类型
<span>#if</span>用于判断变量值,以下代码仅在微信和支付宝端会显示打印对应的内容,在其他端则无打印:
/* #if name == 'wechat' */
console.log('这句话只会在微信上显示')
/* #endif */
/* #if name == 'alipay' */
console.log('这句话只会在支付宝上显示')
/* #endif */
jsonc/json5 文件类型
虽然 .json 文件无法编写注释,但 MorJS 友好的兼容了 .jsonc 和 .json5 文件,例如以下 json 文件仅在微信和支付宝端会加载对应的自定义组件。
{
"component": true,
"usingComponents": {
// #if name == 'wechat'
"any-component": "./wechat-any-component",
// #endif
// #if name == 'alipay'
"any-component": "./alipay-any-component",
// #endif
"other-component": "./other-component"
}
}
4.2 文件维度
以组件为例,默认情况下,组件都包含了 axml/acss/js/json 四个文件。
└── components
└── demo
├── index.axml
├── index.acss
├── index.js
└── index.json
若在微信小程序端,定制化需求或逻辑差异较大,可以直接用 .wx 来做区分。
└── components
└── demo
├── index.axml
├── index.acss
├── index.js
├── index.json
├── index.wx.axml(微信版本)
├── index.wx.acss(微信版本)
└── index.wx.js(微信版本)
在编译输出时,针对微信端的编译构建,会优先用 <span>.wx</span>的版本来生成对应的微信版本源文件,而在引用该组件的页面的 json 中的 usingComponents 是不需要做任何修改的,依然保留原本的引用路径的。05
结语
条件编译让一码多端框架的跨端转换能力变得更加完善,弥补了平台差异化和产品定制化的场景需求,在解决适配问题的同时,减少了不必要的冗余代码,提高代码的质量和可维护性。最后,MorJS 作为一套基于小程序 DSL 的可扩展的多端研发框架,使用者只需书写一套(微信或支付宝)小程序,就可以通过 MorJS 的转端编译能力,将源码分别编译出可以在不同端(微信/支付宝/百度/字节/钉钉/快手/QQ/淘宝/Web…)运行的产物,欢迎大家交流和使用。相关链接
[01] GitHub:https://github.com/eleme/morjs




