
什么是LoRA模型,如何使用和训练LoRA模型?你想要的都在这!
什么是LoRA模型
LoRA的全称是LoRA: Low-Rank Adaptation of Large Language Models,可以理解为stable diffusion(SD)模型的一种插件,和hyper-network,controlNet一样,都是在不修改SD模型的前提下,利用少量数据训练出一种画风/IP/人物,实现定制化需求,所需的训练资源比训练SD模要小很多,非常适合社区使用者和个人开发者。LoRA最初应用于NLP领域,用于微调GPT-3等模型(也就是ChatGPT的前生)。由于GPT参数量超过千亿,训练成本太高,因此LoRA采用了一个办法,仅训练低秩矩阵(low rank matrics),使用时将LoRA模型的参数注入(inject)SD模型,从而改变SD模型的生成风格,或者为SD模型添加新的人物/IP。用数据公式表达如下,其中 W_{0} 是初始SD模型的参数(Weights), BA 为低秩矩阵也就是LoRA模型的参数, W 代表被LORA模型影响后的最终SD模型参数。整个过程是一个简单的线性关系,可以认为是原SD模型叠加LORA模型后,得到一个全新效果的模型。
W = W_{0} + BA
在著名的模型分享网站https://civitai.com/上,有大量的SD模型和LoRA模型,其中SD模型仅有2000个,剩下4万个基本都是LoRA等小模型。例如下图,水墨画和原神八重神子就是LoRA模型来实现特定的画风和人物IP。
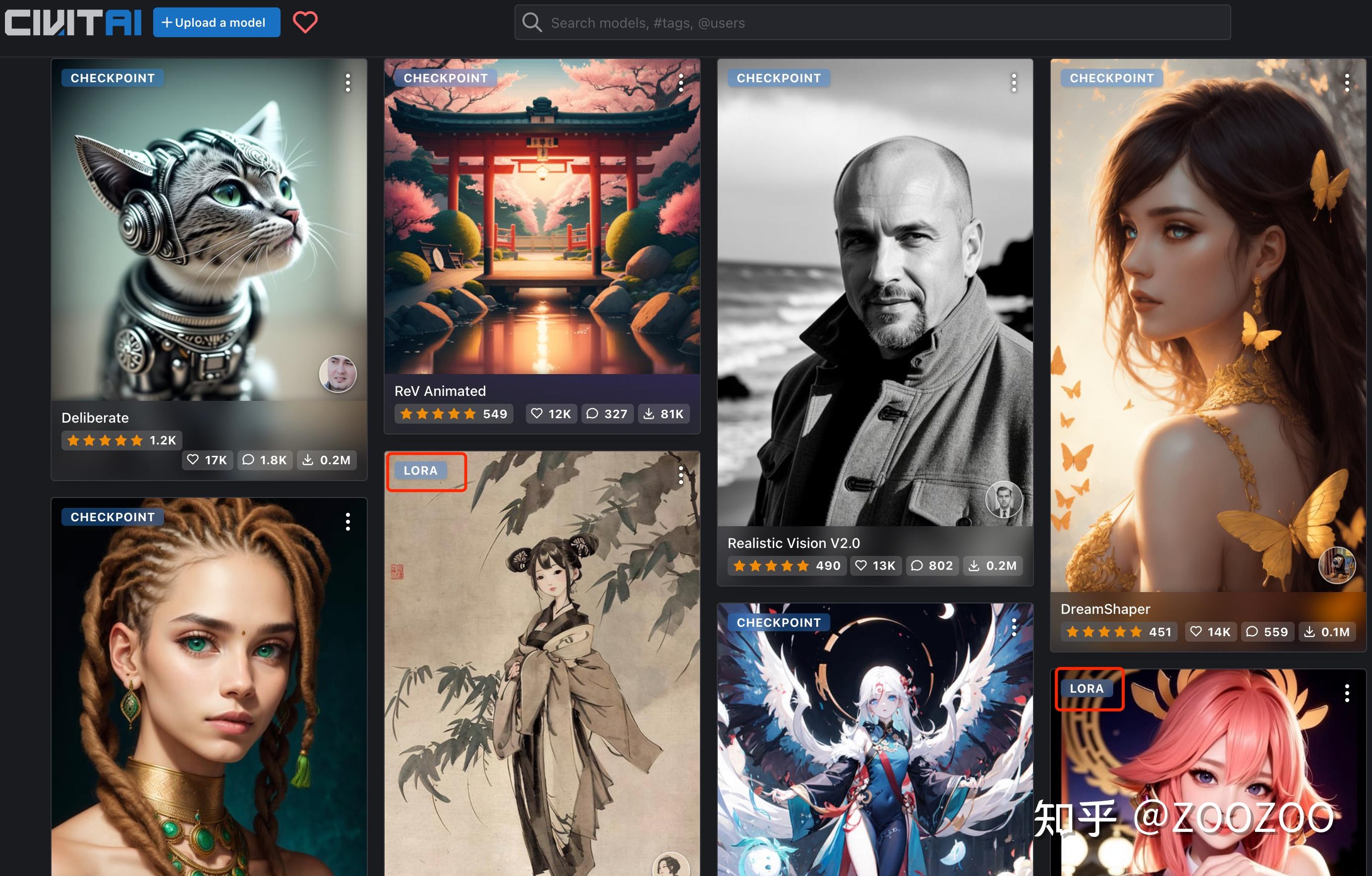
在模型分享网站civitai上,左上角标注了CHECKPOINT的代表的是SD模型,标注了LORA的就是LORA模型了
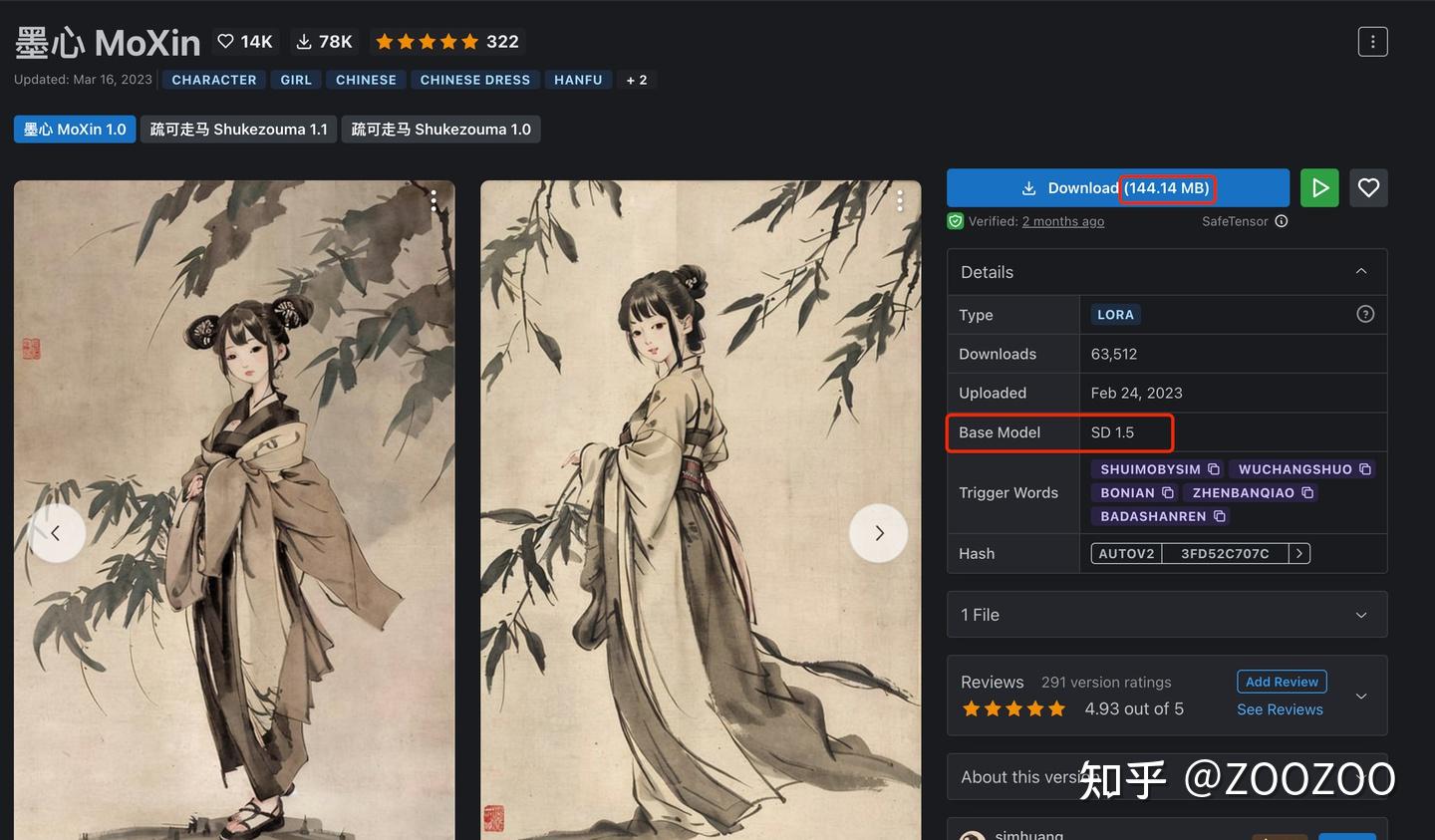
以下是一个LoRA模型详解分析,从下图可以看到,该模型只有144MB,相比SD模型至少2GB起步,LORA确实算得上是小模型,非常适合硬件资源受限的用户。值得注意的是,LORA是SD模型的插件网络,所以必须配合SD一起使用。图中标注了Base Model: SD 1.5,意味着该模型是基于SD 1.5训练的,并且在使用时必须配合SD 1.5才能生成想要的效果。
由于目前civaitai已经屏蔽了中国用户的访问,所以需要科学上网。推荐下我们的civitai模型镜像网站https://aigccafe.com/,国内用户可以顺畅访问,无需百度网盘下载,飞一般的下载速度。详细介绍在另一篇回答里,ZOOZOO:5万多个Stable Diffusion/LoRA模型!国内版Civitai!
如何使用LORA模型
目前社区使用者绝大部分都是基于stable-diffusion-webui这个开源项目,一些相关的整合包(例如秋叶,星空)也是在此基础上进行的简化。因此在这里仅基于这个webui这个项目介绍。
假设你已经完成了webui的安装,将下载的LORA模型放置在文件夹下 “stable-diffusion-webui/models/Lora”文件夹下,以下以水墨画风格的LoRA为例

只需要在生成的时候,prompt增加关键词即可,以上述下载的LoRA模型Moxin_10为例,需要在prompt中增加以下关键字,0.5代表LoRA的强度,可自由调节
以下是实战效果,在输入好prompt后,在最后增加 ,生成如下图片:
Prompt: ((shuimobysim, traditional chinese ink painting)), masterpiece, best quality, fullbody, 1girl, dancing, dynamic pose, wearing white techwear jacket, modelshoot style, posing for a picture, long legs, (standing in a chinese garden)

如何训练LoRA模型 – 定制你的专属模型
假设你想将自己形象加入模型中,那你需要首先进行数据收集,将自己的照片作为训练数据,训练新的模型并保存。
数据准备;首先收集图片,可以通过爬虫或者直接从搜索引擎下载,这里我们选择直接从百度图片搜索下载。注意,数据准备的质量决定了你最终模型的效果,如果你喂给模型的图是低质量的图,那么模型给你生成的图也是低质量的图,所以尽量保证图片清晰,分辨率较高,无遮挡。这里我们选择下载蔡徐坤的若干张图片,训练一个人物模型。
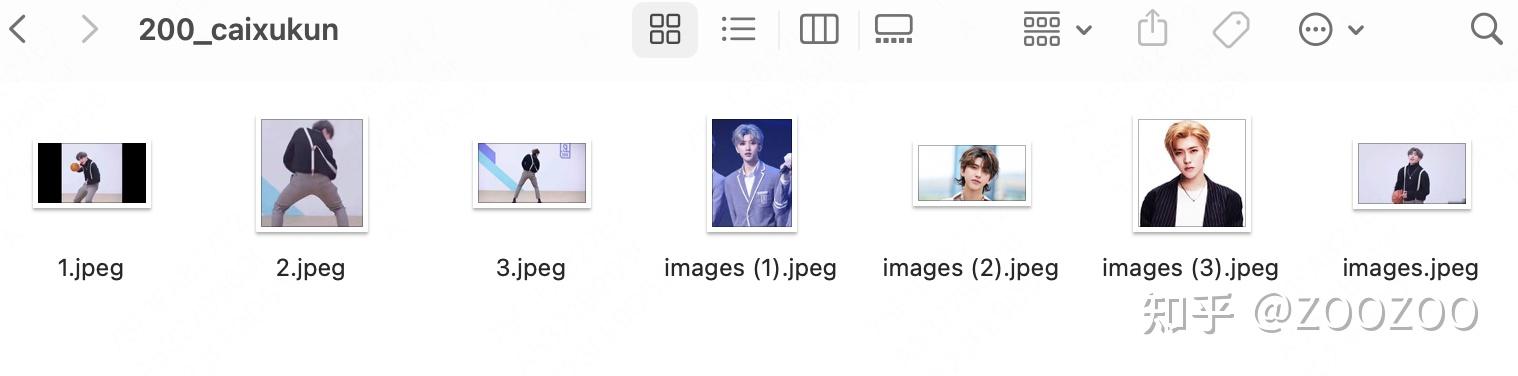
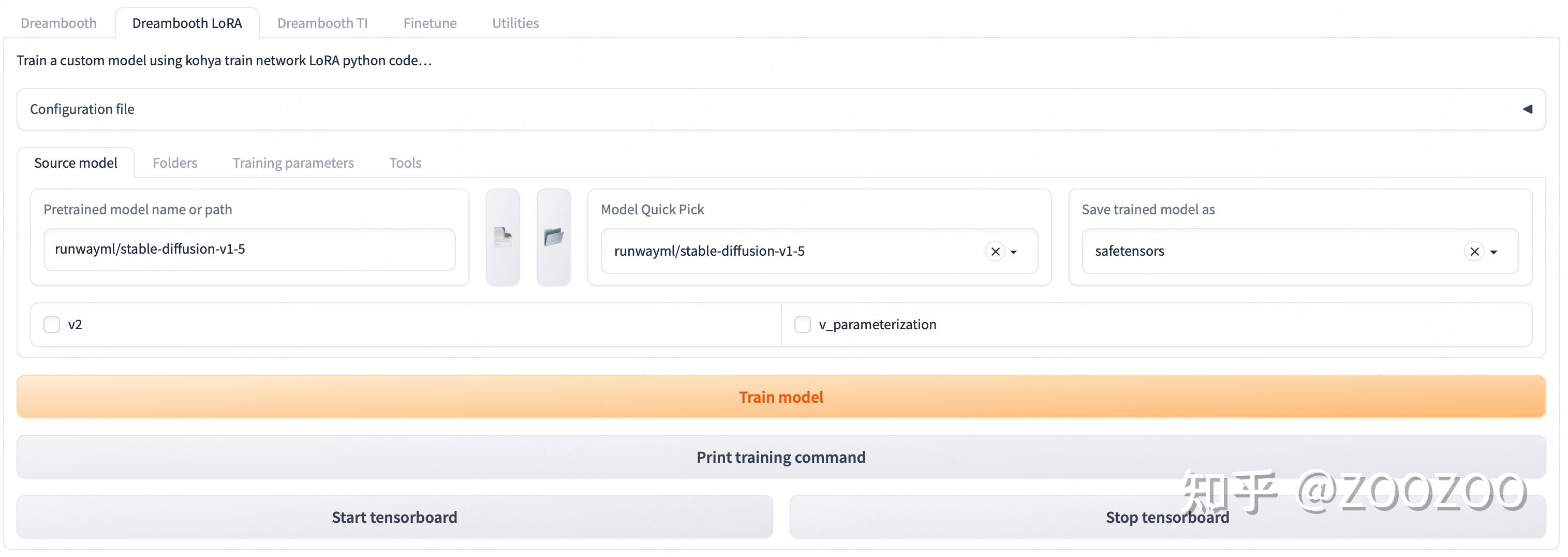
训练模型;这里推荐使用带GUI的工程kohya_ss,适合没有程序经验的读者使用。按照安装说明完成安装后,打开GUI为以下界面,选择Dreambooth LoRA界面。
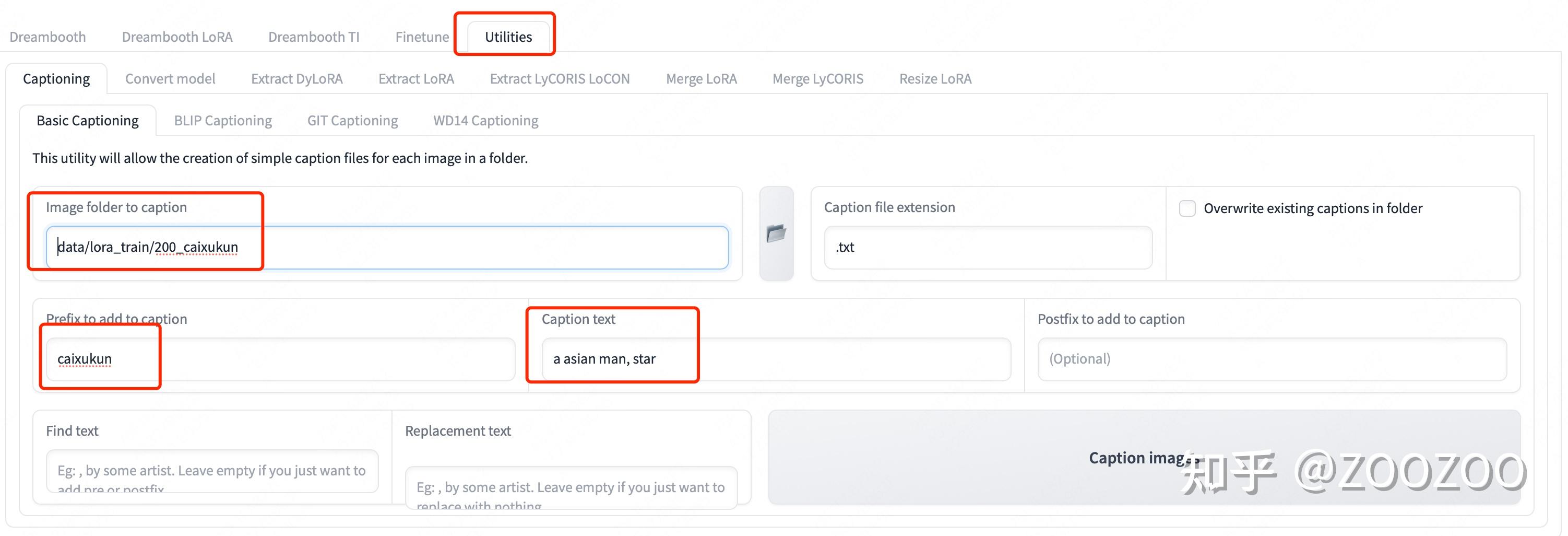
为图片打上标签(caption),输入图片的位置,选择Basic Caption,在Prefix项加上你的关键词,例如我们这里关键词命名为caixukun,可以给图片增加更详细的表述,例如a asian man, star。注意,这个关键词和描述非常重要,在生成图片的时候输入这个关键词,才能生成我们想要的效果。
将文件重命名,加上前缀200_,意味着图片要重复200遍,整个训练过程的总steps数为200 * 图片数量
将文件夹重命名为200_caixukun,放置在文件夹下data/lora_train下
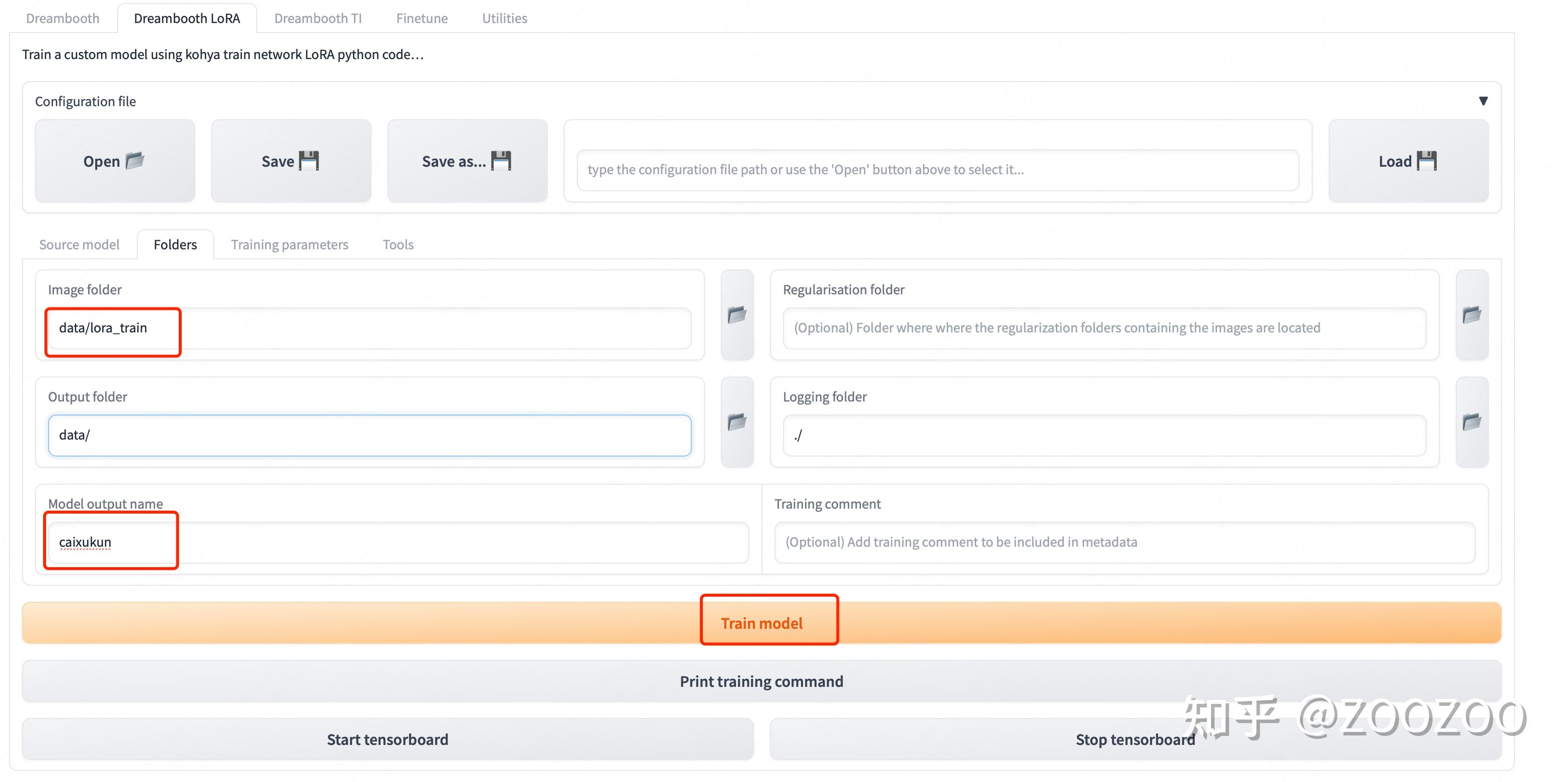
开始训练,切换到如下页面,输入图像的路径data/lora_train,模型命名,点击开始训练。注意200_caixukun文件夹是lora_train的子文件夹,这里路径不要写错了
将训练生成好的模型caixukun.safetensors移动到stable-diffusion-webui/models/Lora文件夹下,输入以下prompt,测试一下效果
caixukun, a aisan man, star,
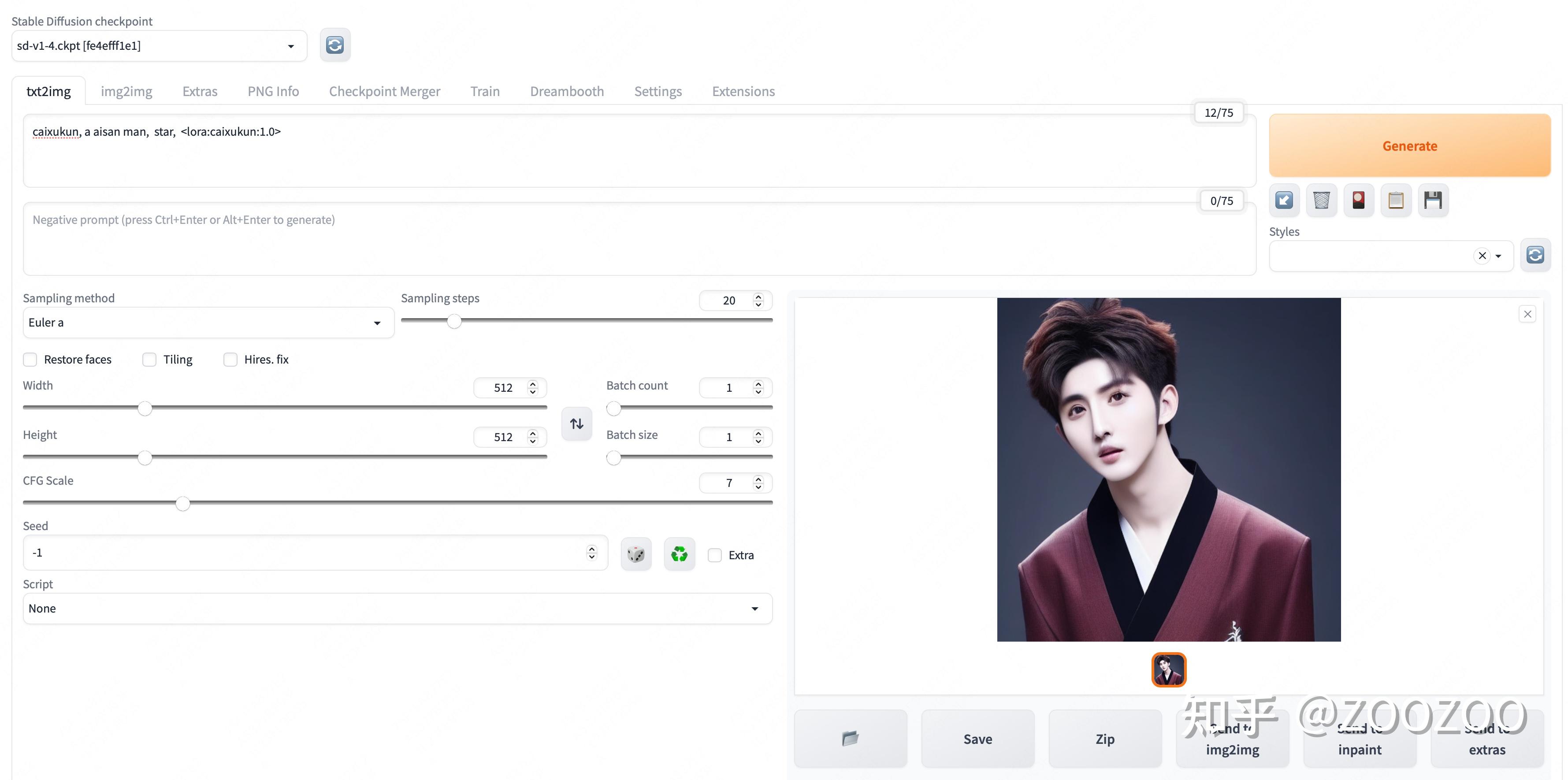


因为这里只随便选用了7张照片,因此效果不算很好,只能说有一点神似。如果要训练一个高质量的模型,建议准备50张以上的图片。
———————————05.12更新—————————————-
这次获取了更多图片,又训练了一个画风LoRA模型。训练集包含2000张高质量图片,由小红书@mimilulu 提供,质量非常之高。
训练采用V100,总共训练20000步,花费4个小时,以下是由该模型生成的一些图片






