
LLM Agent工作流中Prompt精华解析
在与大模型交互的过程中,提示词是很关键的,也是成本最低解决幻觉的有效方法。所以一定要给它一些Example,在没有一个不包含Example,结果往往是不理想的。虽说网上也有介绍Zero Shot 的Prompt,比如Let’s think step by step,但遇到稍微复杂点的任务,它就不一定能达到自己想要的效果。
一个精心设计完成特定任务的Prompt大体需要包含这几部分:
- 解决任务的方法
- 任务的输入和输出
- 任务的Example,3到5个左右。
- 任务的历史纪录,如果有的话
- 用户输入的问题。
下面我们一起来看看一些案例:
一、ReAct Prompt
ReAct 提供了一种更易于人类理解、诊断和控制的决策和推理过程。它的典型流程如下图所示,可以用一个有趣的循环来描述:思考(Thought)→ 行动(Action)→ 观察(Observation),简称TAO循环。
循环迭代以上流程,如下图:
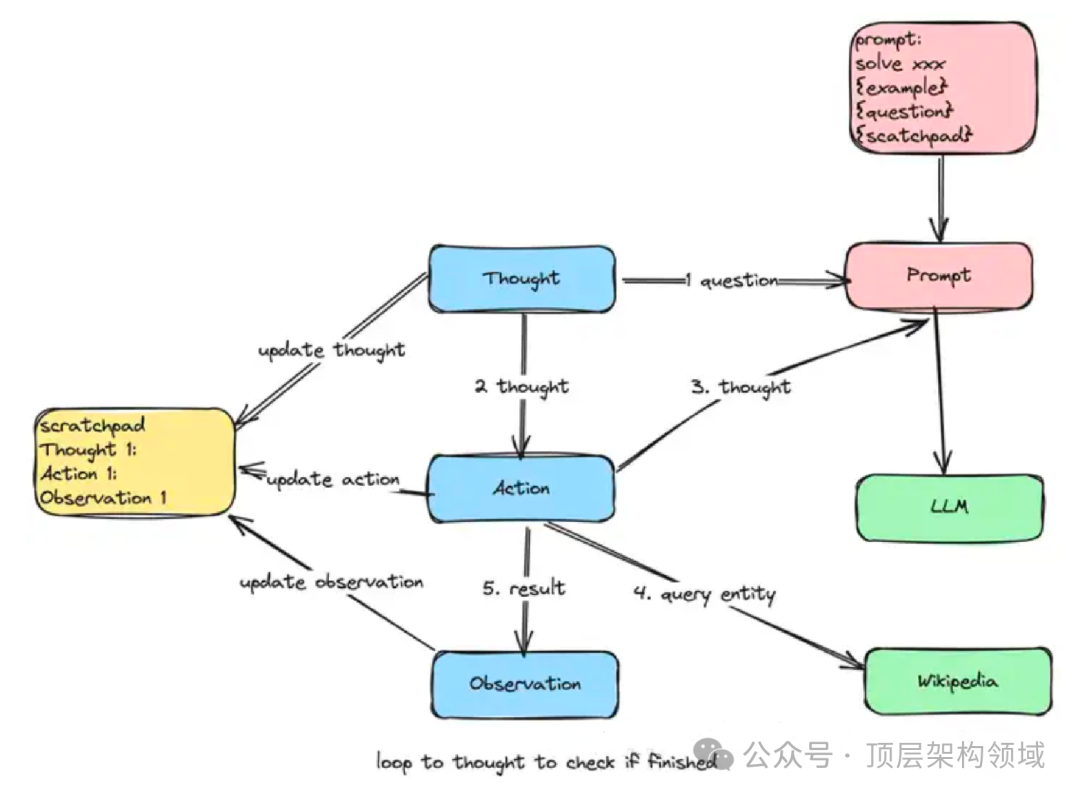
Prompt设计如下所示:包含了说明解决问题的方法、输入和输出、样例和用户问题。
用交替进行的"思考、行动、观察"三个步骤来解决问答任务。思考可以对当前情况进行推理,而行动必须是以下三种类型:
(1) Search[entity],在维基百科上搜索确切的实体,并返回第一个段落(如果存在)。如果不存在,将返回一些相似的实体以供搜索。
(2) Lookup[keyword],在上一次成功通过Search找到的段落中返回包含关键字的下一句。
(3) Finish[answer],返回答案并结束任务。
你可以采取必要的步骤。确保你的回应必须严格遵循上述格式,尤其是行动必须是以上三种类型之一。
以下是一些参考示例:
问题: 科罗拉多造山运动东部地区的海拔范围是多少?
思考1: 我需要搜索科罗拉多造山运动,找到科罗拉多造山运动东部地区的范围,然后找到该地区的海拔范围。
行动1: 搜索[科罗拉多造山运动]
观察1: 科罗拉多造山运动是科罗拉多州及周边地区的一次造山运动(造山运动)。
思考2: 它没有提到东部地区。所以我需要查找东部地区的信息。...
(例子结束)
Question:{question}
{scratchpad}二、CoT 思维链 Prompt
Chain-of-Thought(CoT)是一种改进的Prompt技术,目的在于提升大模型LLMs在复杂推理任务上的表现,对于复杂问题尤其是复杂的数学题大模型很难直接给出正确答案。
思维链就是一系列中间的推理步骤(a series of intermediate reasoning steps)。通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能。

CoT式Prompt示例:
COT = """相关背景: 尼罗河是世界上最长的河流,长度约为6,650公里(4,132英里)。它流经东北非的十一国,包括埃及、苏丹和乌干达。
问题: 世界上最长的河流是什么?
思考: 这个问题询问世界上最长的河流,根据提供的背景信息,我知道是尼罗河。
行动: 完成[尼罗河]
...
"""三、思维树(Tree-of-thought, ToT)Prompt
对 CoT 的进一步扩展,在思维链的每一步,推理出多个分支,拓扑展开成一棵思维树。使用启发式方法评估每个推理分支对问题解决的贡献。选择搜索算法,使用广度优先搜索(BFS)或深度优先搜索(DFS)等算法来探索思维树,并进行前瞻和回溯。
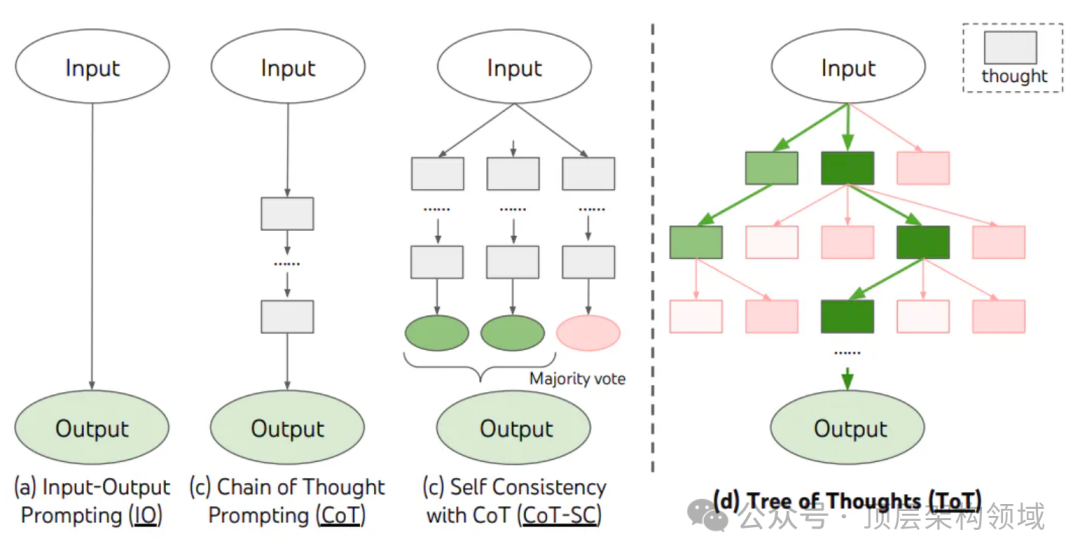
思维树Prompt示例:
假设我们要解决以下问题:“一个矩形花园的长度是宽度的两倍,如果它的周长是60米,那么它的面积是多少平方米?”
步骤1:定义问题
任务:确定矩形花园的面积。
已知:长度是宽度的两倍;周长是60米。
步骤2:分解问题
识别变量:设宽度为w,长度为2w。
使用公式:周长 = 2 * (长度 + 宽度)
替换已知:60 = 2 * (2w + w)
步骤3:求解方程
简化方程:60 = 2 * (3w)
解方程:60 = 6w
得出宽度:w = 10米
步骤4:计算长度
长度 = 2 * 宽度
长度 = 2 * 10 = 20米
步骤5:计算面积
面积 = 长度 * 宽度
面积 = 20 * 10 = 200平方米四、反思Prompt
反思或者说精炼,是一种在现有问答基础上更进一步地指导模型进行自我优化和排除错误答案的过程。
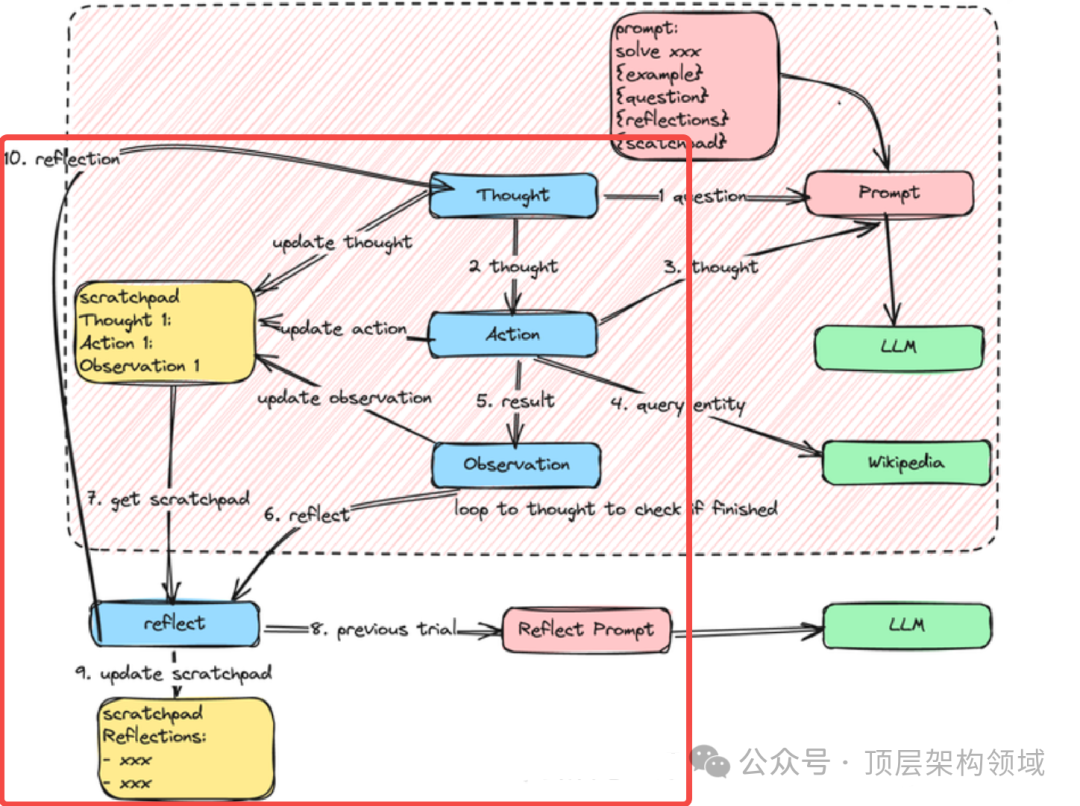
反思Prompt示例:
之前的尝试:
问题: 《罗马议定书》由三位总理签署,其中一位被暗杀是作为什么的一部分?
思考1: 我需要搜索《罗马议定书》,找到这三位总理
...
行动3: 完成[第二次世界大战]
反思: 我搜索了参与签署的一位总理,然后试图立即回答。我应该搜索每位总理,然后查看每位总理的“死亡”信息,以获取更多信息后再回答。五、工具调用Prompt
如果你有大量的工具函数可能会被调用,但你显然无法将所有Tools发给LLM,这可能会超过大模型的Token限制。你要怎么处理呢?一个简单的方法是采用分组,尽量将类似的函数组合到一起,然后再选择。
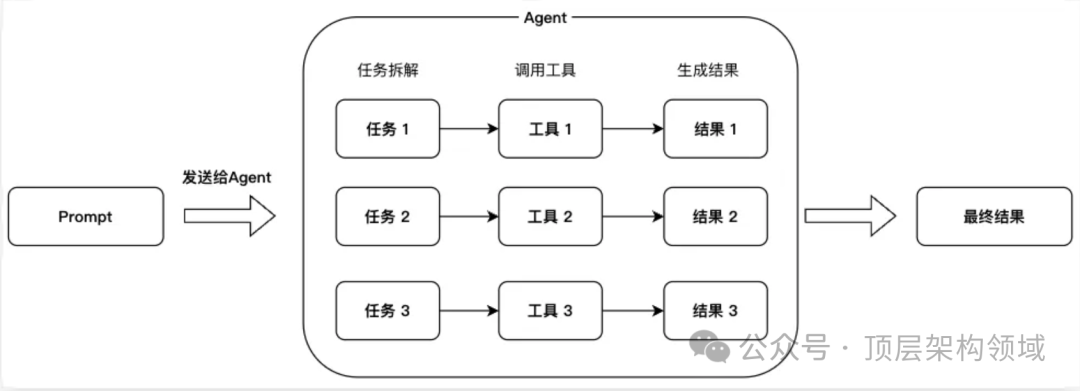
工具调用示例:
任务必须从以下选项中选择:
"token-classification"、"text2text-generation"、"summarization"、"translation"、"question-answering"、"conversational"、"text-generation"、"sentence-similarity"、"tabular-classification"、"object-detection"、"image-classification"、"image-to-image"、"image-to-text"、"text-to-image"、"text-to-video"、"visual-question-answering"、"document-question-answering"、"image-segmentation"、"depth-estimation"、"text-to-speech"、"automatic-speech-recognition"、"audio-to-audio"、"audio-classification"、"canny-control"、"hed-control"、"mlsd-control"、"normal-control"、"openpose-control"、"canny-text-to-image"、"depth-text-to-image"、"hed-text-to-image"、"mlsd-text-to-image"、"normal-text-to-image"、"openpose-text-to-image"、"seg-text-to-image"。
可能存在多个相同类型的任务。逐步思考解决用户请求所需的所有任务。
解析出尽可能少的任务,同时确保能够解决用户请求。
注意任务之间的依赖关系和顺序。
如果无法解析用户输入,你需要回复空 JSON [],否则必须直接返回 JSON。六、 多智能体Prompt
多智能体提示词设计,大概源于人类的分工合作思想,Prompt如果设定过多的不同任务,很可能会导致大模型无法准确跟随指令,因此给不同的智能体设计专用的Prompt就能让它们工作的更高效。
总结:
以上就是一些常用的LLM Agents工作流中对于Prompt提示词使用与思考。通过精心设计的Prompt,我们可以显著提升LLM在Agent工作流中的表现。理解并应用这些设计原则,将有助于构建更高效、更可靠的AI系统。
声明内容来源于网络


