什么是redis 大key /Big key和Big key的定位以及解决方案
Redis作为开发中常见的中间件之一,其最常见的用途就是缓存数据来提高系统的性能。但是如果缓存使用不当,如下场景:
(1)业务中使用了不恰当的redis数据结构。如使用String的value存储某个较大二进制文件数据。
(2)业务预估不准确;如规划的时候没有对key的成员进行合理的拆分,导致key的成员数据量过多。
(3)没有及时清理无用的数据;如List结构中数据持续增加而没有弹出数据的机制,那么数据会越来越多。
(4)某个key存放的数据突然的波动很大;如存放某个明星热点粉丝列表或者评论的列表由于明星出轨或者离婚导致热点数据量激增,也就是value存放过多数据。
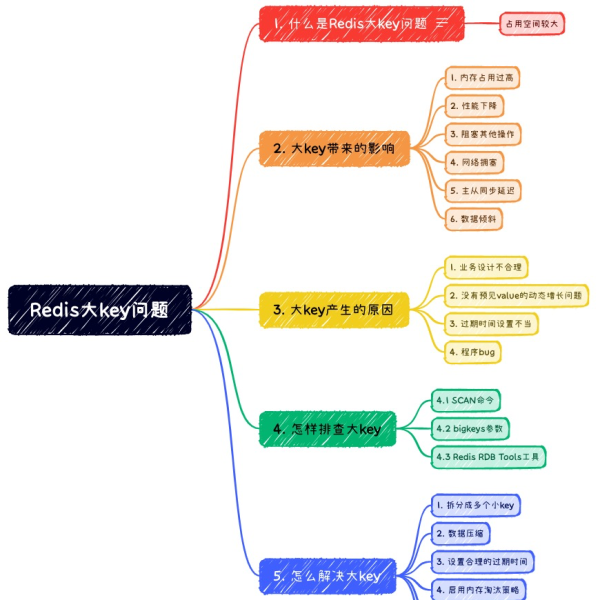
以上情况都会导致key对应的value数据量比较大,也就是value所占的内存空间较大,这就是所谓的big key问题。针对Redis的big key一般的判定标准如下:
总结起来其实就分成两类,一类是字符型,一类是非字符型(Hash、List、Set、Zset),针对字符型是判断value值大小,针对字符型就是判断其存放的元素个数,如下图的整理:
上面是判定big key的一般标准,具体到每个系统的判断标准还需要根据自身的业务场景来确定。
1、big key的危害性
big key产生后会给Redis带来多种的危害,如下列举了几种常见的危害:
(1)内存空间使用不均匀;在Redis集群中,big key可能导致各个节点的内存空间使用不均匀。这可能会引发节点间的负载不均衡,影响整体性能。如下所示:
(2)超时阻塞:由于Redis是单线程的,对big key的操作通常会比较耗时,这可能导致后续的请求被阻塞,增加Redis的响应时间,严重时可能导致服务不可用。如下图所示:
(3)会产生网络拥塞;每次获取big key会产生较大的网络流量,如果此时这个key被访问的频率不高,此时这个big key可以流量高峰过了再处理。
(4)big key会影响redis的主从同步与主从切换;删除一个大key 造成主库较长时间的阻塞并引发同步中断或主从切换等问题。
所以在实际应用中需要定期检查和监控Redis数据库中的big key,发现big key之后采取适当的措施进行处理,以确保系统的稳定性和高效性。
2、定位big key的方法
(1)使用Redis自带的命令识别;Redis自带的客户端redis-cli加上–bigkeys参数可以找到Redis常见的数据类型中big key。这种方式的优点是扫描的时候不阻塞服务,但是定位的big key信息较少、不精确。
(2)使用 debug object key 命令;根据传入的key名称来对key进行分析并返回大量的数据,其中serializedlength的值是该key的序列化长度( serializedlength 不等同于它在内存空间中的真实长度),由于次命令属于调试命令,运行成本高并且阻塞其他请求的执行,所以不推荐使用。
(3)redis-rdb-tools开源工具;实质就是对bgsave命令dump出来的rdb快照文件进行分析,找出big key。此方法的可以获取key详细的信息、支持定制化需求,后续的处理方便;但是需离线操作,定位big key需要较长的时间。
3、解决big key的方案
解决Big Key问题,就是减小key对应的value值的大小。针对String数据结构的话就是减少存储的字符串的长度;针对List、Hash、Set、ZSet数据结构则是减少集合中元素的个数。
(1)对大key进行拆分;将一个Big key拆分为多个key-value这样的小key。
(2)对大key进行清理;对Redis中的大key进行清理,从Redis中删除此类数据。Redis4.0后提供了UNLINK命令,它能够以非阻塞的方式缓慢逐步的清理传入的key,通过UNLINK可以安全的删除大Key。
(3)定期清理失效数据;如果某个key有业务不断以增量方式写入大量的数据,并且忽略了其时效性,这样会导致大量的失效数据堆积。可以通过定时任务(如xxl-job)对失效数据进行清理。
(4)压缩value值;如使用序列化、压缩算法将key的大小控制在合理范围内。
总结:
(1)redis的Big key会给Redis带来的意想不到的危害,需要监控、及时发现和处理big key。
(2)开发过程中需要选用适当的Redis数据结构开发业务,尽量避免big key。