
Mysql深度分页问题的处理方案
在日常的开发中,我们经常需要做页面的分页查询和报表数据统计的功能,Mysql在数据量比较小的时候,是不会出现深度分页的问题,一旦数据量达到百万、千万级别之后,做分页功能的时候就会出现深度分页的问题。如下图展示一个分页查询的案例图:

如果没有做技术处理,直接点击页码4647,页面上就会出现查询很慢(甚至超时无法返回数据)的现象,这就是深度分页。
1、深度分页的原因分析
在Mysql中有主键索引和二级索引之分,主键索引叶子结点上是真实的数据,非叶子结点上存储的是页码和主键值的信息。下图是主键索引的案例图:
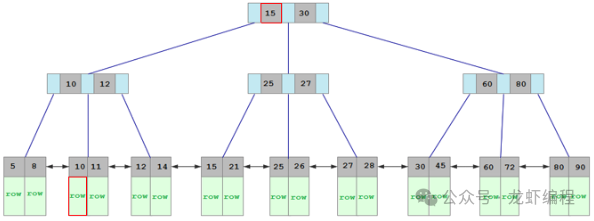
主键索引查询数据的时候从根节点开始查询,先找到主键在下一节点上位置(其实是page页码)根据这个继续定位一下节点上的位置直到找到最终的数据。
二级索引的是非叶子结点上存储的是索引值和页码信息,案例图如下:
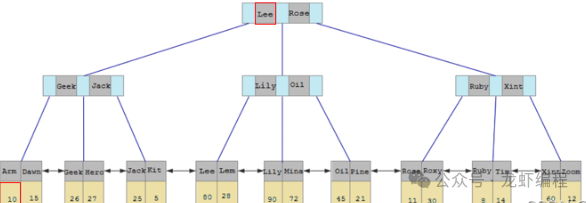
二级索引的叶子结点上存储的是主键值,如果需要获取到行全部数据信息,需要拿到叶子结点上的id到主键索引中继续查询来获取到行全部数据信息。
回表查询:获取二级索引叶子结点上的id再去主键索引中获取id对应的行数据信息的过程。回表查询过程如下图:

假设我们存在一条sql如下:
select * from order where pay_time > '2021-10-01 10:00:00'
limit 10000,10实际上我们只要10条数据,但是Mysql执行过程是

这个过程存在如下的问题:
(1)limit 10000,10,先扫扫描10010行,然后再去弃掉前10000行,返回10行数据;
(2)limit 100000,10 扫描 10010 行数,意味着回表更多的次数,需要执行多次的IO操作,所以这个过程很耗费时间。
深度分页的问题主要是因为需要扫描无效的行数多、回表次数增加最终导致查询的查询需要消耗时间长、效率低。
2、深度分页的优化
针对深度分页出现的原因,我们优化的方向是减少回表次数提高查询效率(如limit 10000,10,我们只要需要查询10条有用的数据,其他的数据都是无效的数据,无效的数据不查询出来)。
(1)标签法
进行分页查询时,我们可以记录上次查询的最后一个id,然后在下次查询时直接从这个id开始查询,避免检索起始位置之前的数据。
SELECT * FROM order WHERE id > #{last_id}
and pay_time > '2021-10-01 10:00:00'
ORDER BY id LIMIT 10;标签法的缺点:
(a)主键必须是自增的;
(b)不支持随机跳页(只能上下翻页)
(2)延迟关联法
延迟关联法的思想是把条件转移到主键索引树来减少回表次数。和标签法不同点是延迟关联使用了 i nner join代替子查询。
select * from order as t
inner join
(select id from order w where w.pay_time >= '2021-10-01 10:00:00'
order by w.pay_time limit 10000,10) as tmp on tmp.id= t.id;延迟关联法的缺点:
(a)可能导致不准确的结果:如果查询中涉及到排序(ORDER BY)和分页,而这个排序依赖于关联表的数据,那么延迟关联可能会导致结果的不准确。
(b)增加查询复杂度:延迟关联可能会使查询变得更加复杂,不易于理解和维护。
(c)可能影响性能:虽然延迟关联可以提高性能,但是在某些情况下,数据库优化器可能不会选择正确的执行计划,导致性能下降。
(3)覆盖索引优化查询
覆盖索引是一种可以直接从索引中获取查询结果,而无需访问数据表的索引。通过使用覆盖索引我们可以减少数据表的访问次数,从而提高查询效率。
(4)数据预处理
可以在数据更新时预先计算出需要查询的结果,并将结果存储在一个单独的表中。这样在进行查询时只需要查询这个表,避免了深度分页;由于需要考虑的点比较多,实际业务一般很少用此方案。
(5)分区和分表
将数据分布到多个表或分区中,我们可以减少单次查询需要处理的数据量,从而提高查询效,如根据ID的范围将数据分布到不同的表中。
#创建订单表
CREATE TABLE order1 LIKE table;
CREATE TABLE order2 LIKE table;
#新增数据的时候 根据id值来存储数据d到指定的表中
SELECI * from order1 WHERE id <= 5000;
INSERT INTO order1;
SELECT * from order2 WHERE id > 5000;
INSERT INTO order2;(6)使用其他的工具辅助
对于全文搜索和复杂查询,可以使用搜索引擎(如Elasticsearch、Solr),它们具有比Mysql更好的分页查询性能,在一定程度上可以解决深分页问题(注意:ES也是存在深度分页问题)。
以上整理了常见的深度分页的处理方案,遇到具体的业务场景的时候需要根据实际的业务来选择适合的方案解决问题。

