如何系统性地学习分布式系统?(下)
我们知道,分布式系统通过多个工作节点来应对单机系统的成本和可用性挑战,但这也带来了对内部节点协调的额外要求。在上一篇文章中,我们探讨了分布式计算中如何进行节点协调。本文将继续讨论分布式存储(有状态)的内部协调机制。同时,上一篇提到的分布式计算协调方式在分布式存储中同样适用,因此在这里不再重复。
分布式存储引入了哪些新的问题?
- 分布式系统的理论与权衡
首先,要理解 ACID、BASE 和 CAP 理论这三个关键主题,可以通过查阅相关文献获取详细信息。 - 如何进行数据分片?
由于单机存储能力无法满足所有数据的需求,必须解决如何将数据按照一定规则分散存储到不同机器的问题。目前常用的分片方案包括 Hash、Consistent Hash 和 Range Based 分片策略,可以了解它们各自的优缺点及应用场景。 -
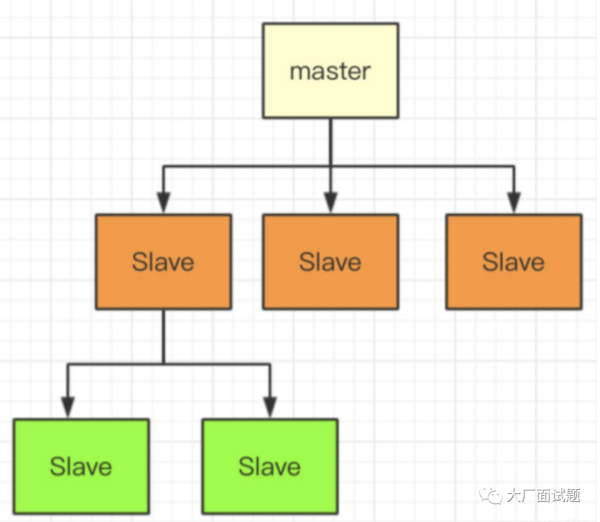
如何进行数据复制?
为了满足系统的高可用性要求,数据冗余处理是必要的。目前的主要方案有中心化方案(如主从复制和一致性协议如 Raft 和 Paxos)以及去中心化方案(如 Quorum 和 Vector Clock)。应了解这些方案的优缺点、各自的应用场景以及它们对外部系统表现的数据一致性级别(如线性一致性、顺序一致性和最终一致性)。
-
如何处理分布式事务?
在分布式系统中,实现事务的首要条件是具备对并发事务进行排序的能力,以便在事务冲突时确认哪个事务成功提交,哪个失败。在单机系统中,这可以通过时间戳和序号轻松实现。然而,在分布式环境中,由于各个机器的时间无法完全同步,单台机器的序号也不具备全局意义,因此这种方法不可行。可以选择在系统中选定一台机器按单机模式生成事务 ID,同城多中心或短距离异地多中心都能适用,但对于全球分布式系统来说,每次事务都去一个节点获取事务 ID 的成本则过高。Google 的 Spanner 通过 GPS 和原子钟实现 TrueTime API,有效解决了这一问题,实现了全球分布式数据库的功能。获得事务 ID 后,可以通过 2PC 或 3PC 协议来实现分布式事务的原子性。
进阶学习阶段
-
实践研究
从实践的角度出发,研究目前比较常用的分布式系统设计,包括:HDFS 或 GFS(分布式文件系统)、Kafka 和 Pulsar(分布式消息队列)、Redis Cluster 和 Codis(分布式缓存)、MySQL 的分库分表(传统关系型数据库的分布式解决方案)、MongoDB 的副本集和分片机制,以及去中心化的 Cassandra(NoSQL 数据库)、中心化的 TiDB 和去中心化的 CockroachDB(NewSQL),还有一些微服务框架等。
-
理论研究
从理论层面深入研究与分布式系统相关的论文是非常重要的。一种有效的方法是阅读《数据密集型应用系统设计》这本书,建议先通读整本书,然后针对感兴趣的章节深入研究其中提到的参考文献。完成这一步后,如果希望成为高级程序员,就需要具备分布式系统的架构与设计能力。
然而,这个过程面临环境障碍,只有一些中大规模的互联网企业才有开发大规模分布式系统的实际需求。因此,只有少数在一线互联网公司的架构师和开发者有机会接触并掌握分布式系统设计技术。而对于大多数普通开发者来说,他们所在的企业往往缺乏相关的开发场景和需求,这使得他们没有机会接触和实践分布式系统设计技术。