如何系统性地学习分布式系统(上)?
在学习一门知识之前,先了解它的背景与发展脉络是一种有效的方法。也就是要明白这个知识是如何产生的、它的目的是什么、它解决了哪些具体问题以及它可能引发了哪些新的挑战(没有万能的解决方案)。这样做可以帮助我们抓住核心要点,不至于陷入细节而迷失方向。因此,在开始学习分布式系统之前,我们首先需要回答一个关键问题:分布式系统是为了解决哪些问题而产生的?
分布式系统解决了什么问题?
首先,单机系统的性能限制带来了成本问题。随着摩尔定律逐步失效,廉价 PC 的性能已经达到了瓶颈。尽管小型机和大型机能够提供更高的单机性能,但它们的成本过于高昂,令大多数企业难以负担。
其次,用户数量和数据量的爆炸性增长也对成本构成了巨大挑战。进入互联网时代,用户数量和数据量都呈现指数级增长。然而,单个用户或数据的价值较软件时代相比有所降低,因此必须寻找更加经济高效的解决方案。
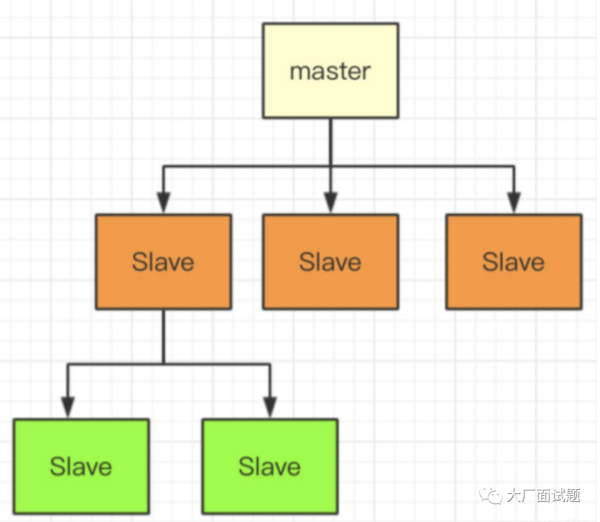
最后,业务的高可用性需求也是至关重要的因素。互联网产品需要全天候 7×24 小时持续提供服务,任何停机或故障都是无法接受的。为实现高可用性,唯一的方式是增加系统冗余。即便单机系统可以承载业务需求,出于对高可用的要求,系统最终还是需要转向分布式架构。
从上述三个原因可以看出,在互联网时代,单机系统已经无法有效解决成本和高可用性问题,而这两个问题对于几乎所有企业来说都是至关重要的。因此,从单机系统过渡到分布式系统,成为了一种不可避免的技术趋势。
分布式系统是怎么解决问题的?
那么,分布式系统是如何解决单机系统在成本和高可用性上的问题呢?其实原理非常简单,就是通过网络将多台廉价的 PC 连接起来,协同处理任务。同时,系统引入冗余机制,以确保即使某些节点出现故障,整体系统依然能够保持高可用性。
分布式系统引入了哪些新的问题?
分布式系统由一组通过网络相互通信、协同完成任务的计算节点组成。从它的定义中可以看出,分布式系统通过多个节点的协作来解决单机系统在成本和可用性上的问题。然而,这也引入了如何协调这些分布式节点之间工作的新问题。我们常说,掌握一项知识需要理解它的前因后果。对于分布式系统来说,前因是“分布式系统解决了哪些问题”,而后果则是“它如何协调内部节点的工作”。因此,我们需要探讨的第二个关键问题是:分布式系统如何实现工作节点之间的协调?
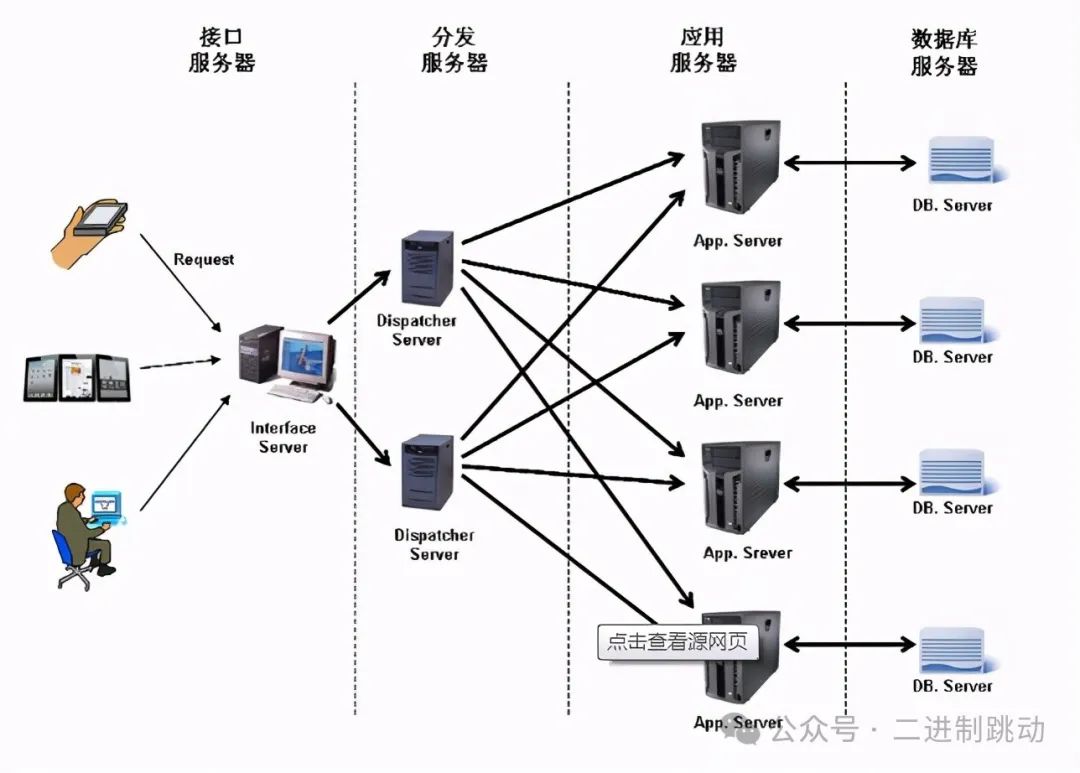
分布式计算引入了哪些新的问题?
- 如何找到服务?
在分布式系统中存在多种服务,服务 A 如何找到服务 B 是一个必须解决的问题。通常采用服务注册与发现机制来实现。这可以通过了解服务注册发现的实现原理来解决,并且还可以思考在这种机制下,选择做成 AP 系统还是 CP 系统更合理。 - 如何找到实例?
找到服务后,接下来的问题是:当前请求该发送到该服务的哪个实例?通常情况下,如果同一服务的实例都是无状态且完全对等的,那么负载均衡策略就足够解决问题。如果实例有状态,需通过路由服务先确定请求数据所属的实例,然后再进行访问。 - 如何避免雪崩?
防止系统崩溃的策略相对清晰,主要有两种思路:一是通过快速失败和降级机制(如熔断、限流等)迅速减轻系统的负载,避免发生雪崩;二是通过弹性扩容机制快速增加系统的服务能力,以防止过载。根据不同场景,可以选择其中一种策略,或同时采用两者。快速失败可能会导致部分请求失败,特别是在一致性要求较高的系统中,可能引发数据不一致的问题。而弹性扩容虽然更为理想,但其实现成本和响应时间都比快速失败要高得多。 - 如何进行监控和告警?
对分布式系统而言,如果无法清楚了解内部运行状态,就无法保证高可用性。因此,完善的监控机制、分布式追踪、模拟故障的混沌工程,以及相应的告警系统,都是必不可少的保障措施。