
Hugging Face 超详细介绍和使用教程
文章目录
- 一、前言
- 二、可以获得什么?
- 三、入门实践
-
- 3.1 帮助文档
- 3.2 安装
- 3.3 模型的组成
- 3.4 BERT模型的使用
-
- 3.4.1 导入模型
- 3.4.2 使用模型
-
- 3.4.2.1 tokenizer
- 3.5 model
- 3.6 后处理
一、前言
Hugging Face 起初是一家总部位于纽约的聊天机器人初创服务商,他们本来打算创业做聊天机器人,然后在 github 上开源了一个 Transformers 库,虽然聊天机器人业务没搞起来,但是他们的这个库在机器学习社区迅速大火起来。
目前已经共享了超 100,000 个预训练模型,10,000 个数据集,变成了机器学习界的 github。
其之所以能够获得如此巨大的成功,一方面是让我们这些甲方企业的小白,尤其是入门者也能快速用得上科研大牛们训练出的超牛模型。
另一方面是,这种特别开放的文化和态度,以及利他利己的精神特别吸引人。
Hugging Face 上面很多业界大牛也在使用和提交新模型,这样我们就是站在大牛们的肩膀上工作,而不是从头开始,当然我们也没有大牛那么多的计算资源和数据集。
在国内 Hugging Face 也是应用非常广泛,一些开源框架本质上就是调用 Transfomer 上的模型进行微调(当然也有很多大牛在默默提供模型和数据集)。
很多 NLP 工程师招聘的条目上也明摆着要求熟悉 Hugging Face Transformer 库的使用。
因为他既提供了数据集,又提供了模型让你随便调用下载,因此入门非常简单。你甚至不需要知道什么是 GPT,BERT 就可以用他的模型了。
下面初步介绍下 Hugging Face 里面都有什么,以及怎么调用 BERT 模型做个简单的任务。
参考文献:
https://zhuanlan.zhihu.com/p/535100411二、可以获得什么?
内容:
Hugging Face 的官方网站:
https://huggingface.co/- Datasets:数据集,以及数据集的下载地址;
- Models:各个预训练模型;
- course:免费的 NLP 课程,可惜都是英文的;
- docs:文档。

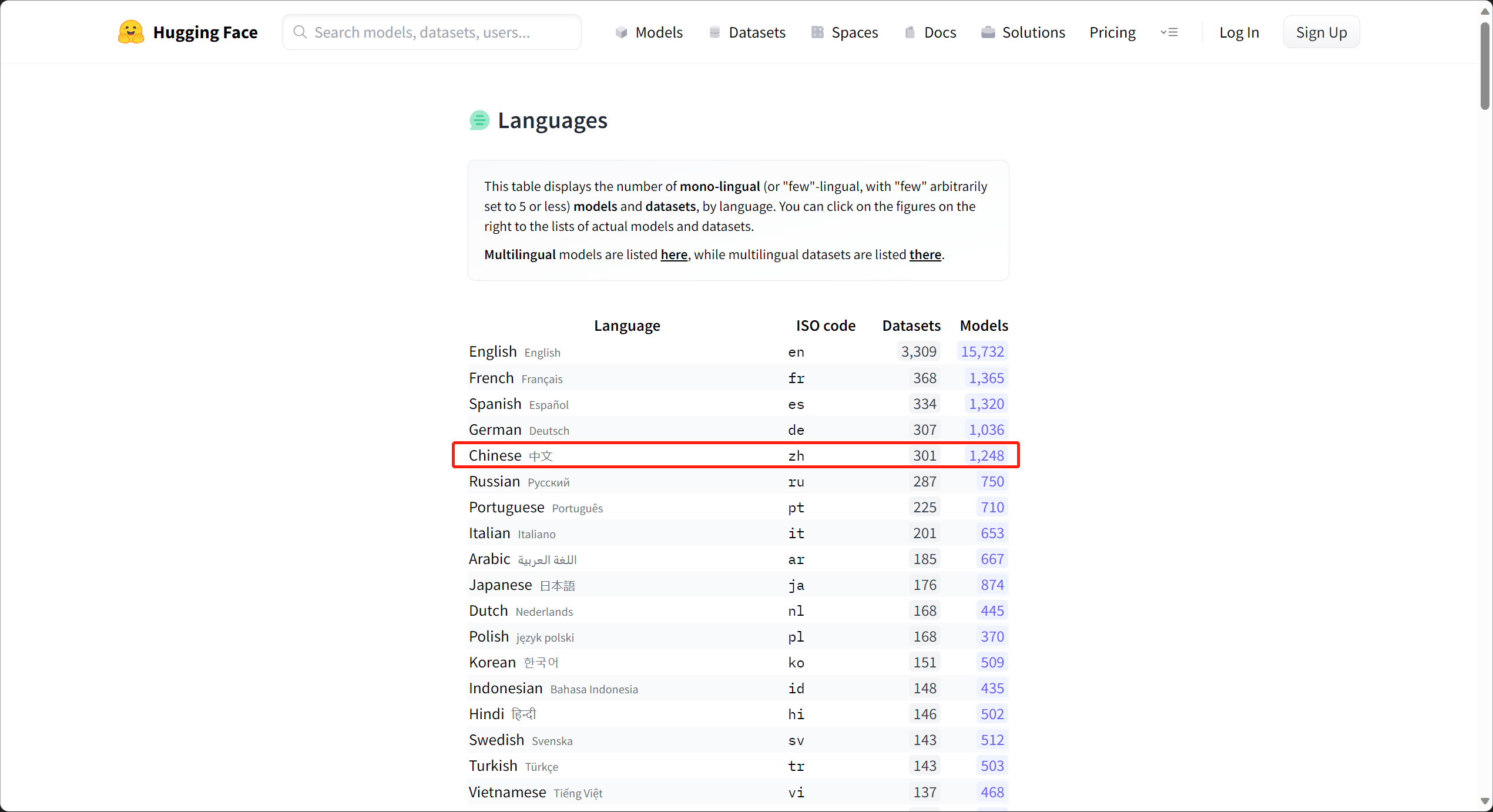
在 NLP 领域,在 Hugging Face 上面数据集和预训练模型的数量以英语为最为众多,远超其他国家的总和(见下图)。
就预训练模型来说,排名第二的是汉语。
就数据集来说,汉语远远少于英语,也少于法,德,西班牙等语言,甚至少于阿拉伯语和波兰语。
这严重跟我想象中的 AI 超级大国及其不匹配。
我想一方面因为数据集的积累都需要很多年,中文常用的(PKU,MSRA)数据集都是十几年前留下的,而我们 AI 和经济的崛起也不过是最近十年的事情。
另一方面,数据集都是大价钱整理出来的,而且可以不断的利用他产生新的模型,这样的大杀器怎可随意公布。发布预训练模型可以带来论文,数据集可啥也带不来,基本上中日韩等的数据集明显偏少。
三、入门实践
3.1 帮助文档
接下来的内容参考了下面的内容,初步带你入门 Hugging Face,简单了解如何调用 BERT 模型:
参考网站:
https://www.cnblogs.com/dongxiong/p/12763923.html
https://huggingface.co/docs/transformers/model_doc/bert
3.2 安装
Transformers 库 github 地址在:
https://github.com/huggingface/transformers
安装方法,在命令行执行(conda 的话在 anaconda propmt):
安装最新的版本:
pip install transformers安装指定版本:
pip install transformers == 4.0如果你是 conda 的话,4.0 以后的版本才会有:
conda install -c huggingface transformers测试下安装是否成功:
from transformers import pipeline3.3 模型的组成
一般 Transformer 模型有三个部分组成:
- tokennizer
- Model
- Post processing
我们可以看到三个部分的具体作用:
Tokenizer 就是把输入的文本做切分,然后变成向量,Model 负责根据输入的变量提取语义信息,输出 logits;最后 Post Processing 根据模型输出的语义信息,执行具体的 NLP 任务,比如情感分析,文本自动打标签等;可见 Model 是其中的核心部分,Model 又可以分为三种模型,针对不同的 NLP 任务,需要选取不同的模型类型:Encoder 模型(如 Bert,常用于句子分类、命名实体识别(以及更普遍的单词分类)和抽取式问答。),Decoder 模型(如 GPT,GPT2,常用于文本生成),以及 sequence2sequence 模型(如 BART,常用于摘要,翻译,生成性问答等)。
说了很多理论的内容,我们可以在 Hugging Face 的官网,随便找一个预训练模型具体看看包含哪些文件。
在这里我举了一个中文的例子 “Bert-base-Chinese”(中文还有其他很优秀的预训练模型,比如哈工大和科大讯飞提供的:roberta-wwm-ext,百度提供的:ernie)。这个模型据说是根据中文维基百科内容训练的,因此语义内容可能不是足够丰富,毕竟其他大佬们提供的数据更多。
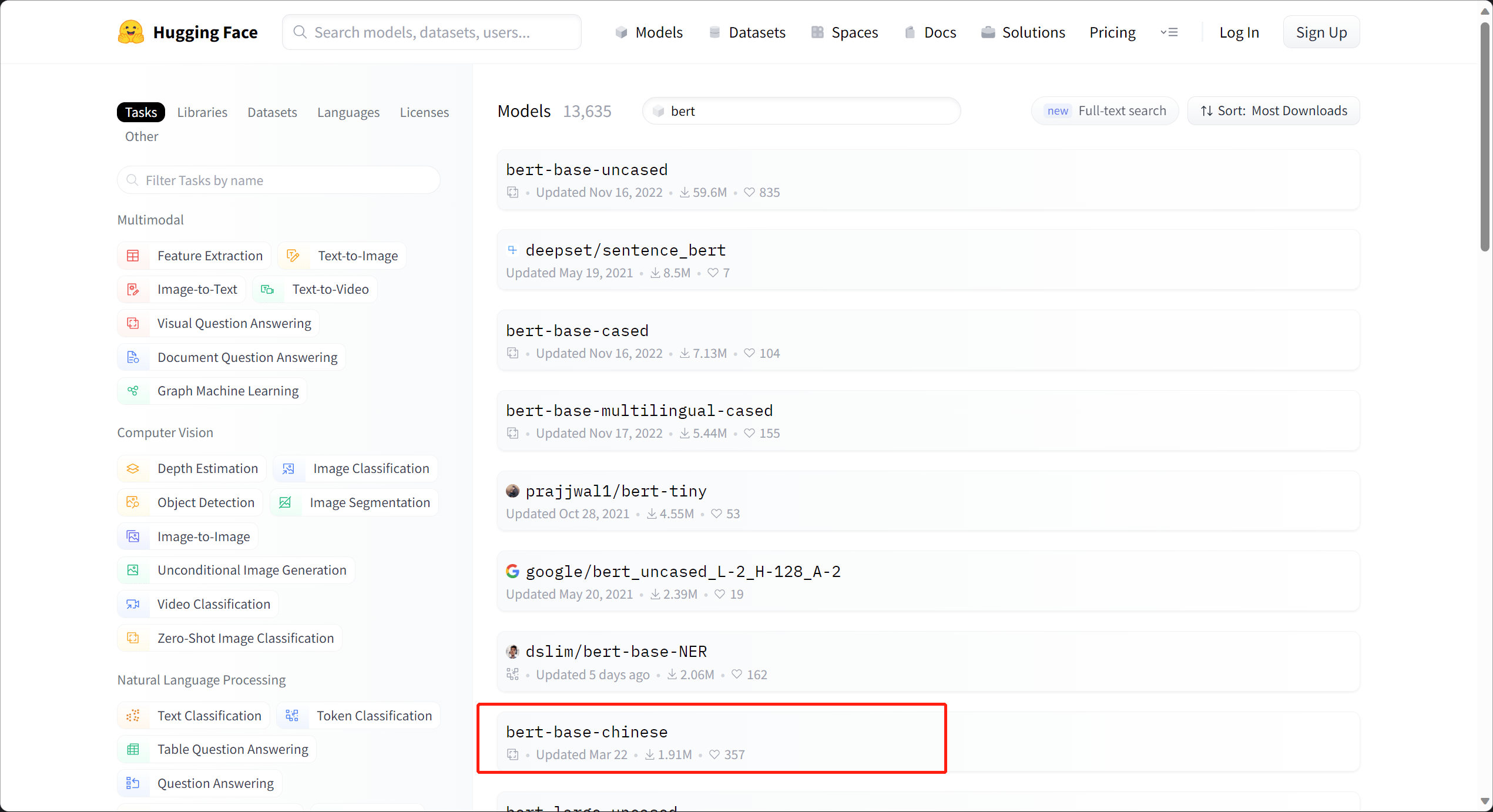
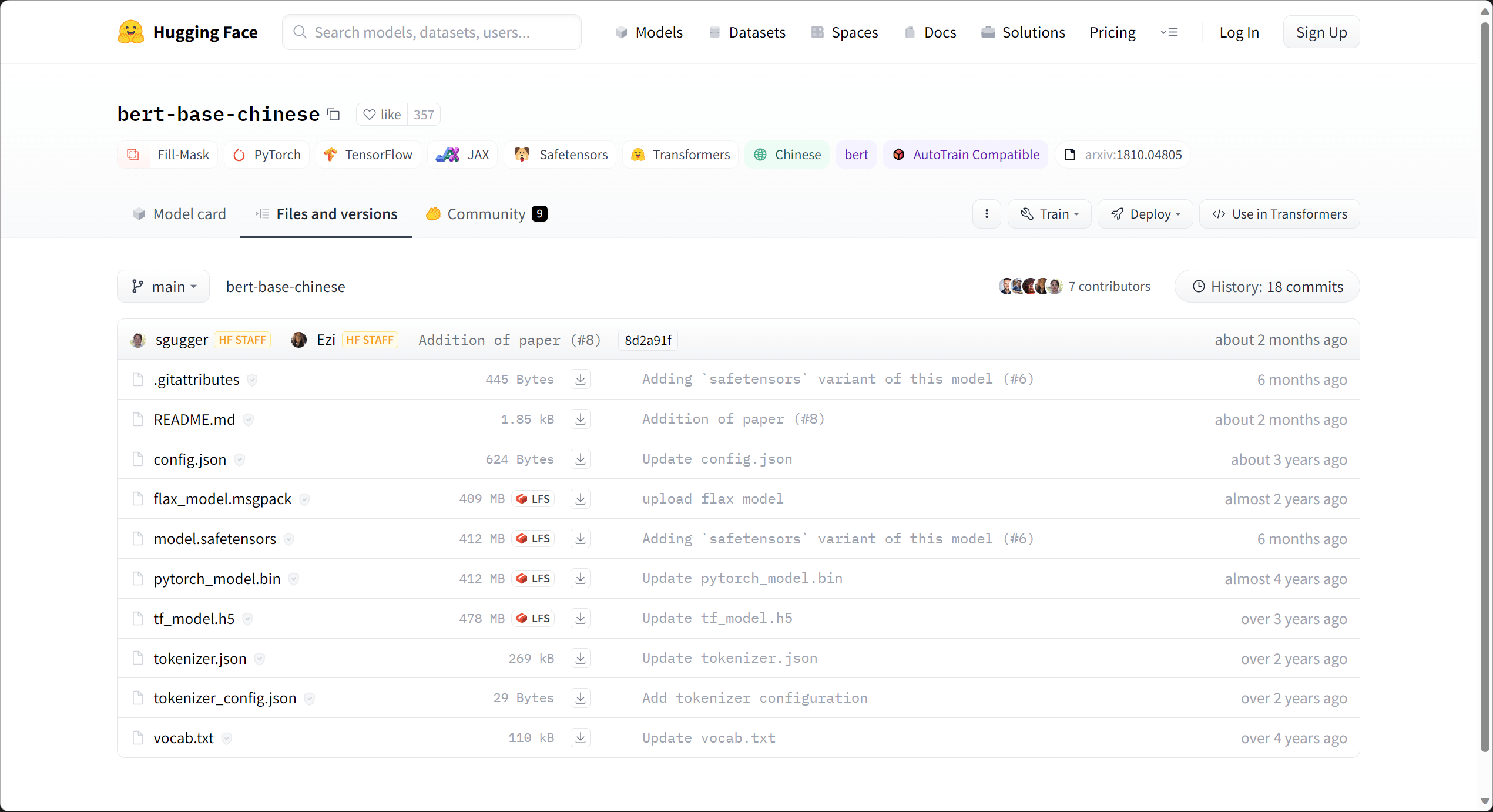
README.md 一般是模型的介绍,包括使用方法都会放到里面,不介绍了。其他最重要的组成部分,大概分为三类:
config:
控制模型的名称、最终输出的样式、隐藏层宽度和深度、激活函数的类别等。这些参数我补齐了说明,对于初学者来说,大家一般不需要调整。这些参数都可以通过 configuration 类更改。
{
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 21128
}tokenizer(包含三个文件):
这些文件是 tokenizer 类生成的,或者处理的,只是处理文本,不涉及任何向量操作。
vocab.txt 是词典文件(打开就是单个字符,我这里用的是 bert-base-chinsese,可以看到里面都是保留符号和单个汉字索引,字符)
tokenizer.json 和 config 是分词的配置文件,根据 vocab 信息和你的设置更新,里面把 vocab 都按顺序做了索引,将来可以根据编码生成 one-hot 向量,然后跟 embeding 训练的矩阵相乘,就可以得到该字符的向量。
模型文件一般是 tensorflow(上图中的 h5 文件)和 Pytorch(上图中的 bin 文件)的都有,因为作者只是单纯的在学习 torch,所以以后的文章都只介绍 torch。
3.4 BERT模型的使用
介绍完了模型库都有哪些内容,下面我们可以导入模型试一试怎么使用:
3.4.1 导入模型
利用官方的 hub 导入模型;下面导入了一个 BertModel ;在官方的教程中推进使用 pipeline 导入模型的方法:
import torch
from transformers import BertModel, BertTokenizer, BertConfig
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
config = BertConfig.from_pretrained('bert-base-chinese')
config.update({'output_hidden_states':True})
model = BertModel.from_pretrained("bert-base-chinese",config=config)利用 pipeline 的方式也是一样的可以导入模型哈,方式如下:
from transformers import AutoModel
checkpoint = "bert-base-chinese"
model = AutoModel.from_pretrained(checkpoint)因为 Hugging Face 官网在国外,自动下载可能比较费劲。
默认下载地址在这里:
- 使用 Windows 模型保存的路径在 C:Users[用户名].cachetorchtransformers 目录下,根据模型的不同下载的东西也不相同;
- 使用 Linux 模型保存的路径在 ~/.cache/torch/transformers/ 目录下
如果自动下载总是中断的话,可以考虑用国内的源,或者手工下载之后指定位置。(Hugging Face 官网,选择 models 菜单,然后搜索自己想要的模型,然后把里面的文件下载下来,其中体积较大的有 tf 的有 torch 的,根据自己需要下载)。
import transformers
MODEL_PATH = r"D:testbert-base-chinese"
# 导入模型
tokenizer = transformers.BertTokenizer.from_pretrained(r"D:testbert-base-chinesebert-base-chinese-vocab.txt")
# 导入配置文件
model_config = transformers.BertConfig.from_pretrained(MODEL_PATH)
# 修改配置
model_config.output_hidden_states = True
model_config.output_attentions = True
# 通过配置和路径导入模型
model = transformers.BertModel.from_pretrained(MODEL_PATH,config = model_config)3.4.2 使用模型
上一步我们已经把模型加载进来了,在这里,尝试一下这个模型怎么样,看看能不能把相关的语义带入进来。
我们之前文章介绍了 bert 的两个任务(MLM 和 NSP),这一节,我们一起测试这两个任务的效果。首先我们逐步来看看 BERT 每个部分的输出都是什么:
3.4.2.1 tokenizer
上面代码可以看到他实例化了 BertTokenizer 类,它是基于 WordPiece 方法的,先看看他有哪些参数:
( vocab_file,do_lower_case = True,do_basic_tokenize = True,never_split = None,unk_token = '[UNK]',sep_token = '[SEP]',pad_token = '[PAD]',cls_token = '[CLS]',mask_token = '[MASK]',tokenize_chinese_chars = True,strip_accents = None,**kwargs )- vocab_file:这里是放置词典的地址;
- do_lower_case,是否都变成小写,默认是 True;
- do_basic_tokenize,做 wordpiece 之前是否要做 basic tokenize;
- 下面的都是一些关键字的确认。
- 还有就是是否分开中文字符,因为bert是面向英文的所有有这些设置,一般不用改,当然我们这里的案例也只是读取了预训练模型。
示例如下,可以看出 BERT 对中文是字符级别的分词,对待英文是到 sub-word 级别的:
print(tokenizer.encode("生活的真谛是美和爱")) # 对于单个句子编码
print(tokenizer.encode_plus("生活的真谛是美和爱","说的太好了")) # 对于一组句子编码
# 输出结果如下:
[101, 4495, 3833, 4638, 4696, 6465, 3221, 5401, 1469, 4263, 102]
{'input_ids': [101, 4495, 3833, 4638, 4696, 6465, 3221, 5401, 1469, 4263, 102, 6432, 4638, 1922, 1962, 749, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1,
1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
# 也可以直接这样用
sentences = ['网络安全开发分为三个层级',
'车辆系统层级网络安全开发',
'车辆功能层级网络安全开发',
'车辆零部件层级网络安全开发',
'测试团队根据车辆网络安全目标制定测试技术要求及测试计划',
'测试团队在网络安全团队的支持下,完成确认测试并编制测试报告',
'在车辆确认结果的基础上,基于合理的理由,确认在设计和开发阶段识别出的所有风险均已被接受',]
test1 = tokenizer(sentences)
print(test1) # 对列表encoder
print(tokenizer("网络安全开发分为三个层级")) # 对单个句子encoder输出结果为:
[101, 4495, 3833, 4638, 4696, 6465, 3221, 5401, 1469, 4263, 102]
{'input_ids': [101, 4495, 3833, 4638, 4696, 6465, 3221, 5401, 1469, 4263, 102, 6432, 4638, 1922, 1962, 749, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
{'input_ids': [[101, 5381, 5317, 2128, 1059, 2458, 1355, 1146, 711, 676, 702, 2231, 5277, 102], [101, 6756, 6775, 5143, 5320, 2231, 5277, 5381, 5317, 2128, 1059, 2458, 1355, 102], [101, 6756, 6775, 1216, 5543, 2231, 5277, 5381, 5317, 2128, 1059, 2458, 1355, 102], [101, 6756, 6775, 7439, 6956, 816, 2231, 5277, 5381, 5317, 2128, 1059, 2458, 1355, 102], [101, 3844, 6407, 1730, 7339, 3418, 2945, 6756, 6775, 5381, 5317, 2128, 1059, 4680, 3403, 1169, 2137, 3844, 6407, 2825, 3318, 6206, 3724, 1350, 3844, 6407, 6369, 1153, 102], [101, 3844, 6407, 1730, 7339, 1762, 5381, 5317, 2128, 1059, 1730, 7339, 4638, 3118, 2898, 678, 8024, 2130, 2768, 4802, 6371, 3844, 6407, 2400, 5356, 1169, 3844, 6407, 2845, 1440, 102], [101, 1762, 6756, 6775, 4802, 6371, 5310, 3362, 4638, 1825, 4794, 677, 8024, 1825, 754, 1394, 4415, 4638, 4415, 4507, 8024, 4802, 6371, 1762, 6392, 6369, 1469, 2458, 1355, 7348, 3667, 6399, 1166, 1139, 4638, 2792, 3300, 7599, 7372, 1772, 2347, 6158, 2970, 1358, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
来看一下这个输出:
对于单个句子是上面那种,它只输出句子 tok 之后的 id,我们注意到已经加好 [CLS], [SEP] 等标识符了;(查询 tokenizer 可知,101 是 [CLS], 102 是 [SEP])除了 input_ids 之外,还自动编码了 token_type_ids,attention_mask。
3.5 model
model 实例化了 BertModel 类,除了初始的 Bert、GPT 等基本模型,针对不同的下游任务,定义了 BertForQuestionAnswering,BertForMultiChoice,BertForNextSentencePrediction 以及 BertForSequenceClassification 等下游任务模型。
模型导出时将生成 config.json 和 pytorch_model.bin 参数文件,这两个文件前面已将介绍了,一个是配置文件一个是 torch 训练后 save 的文件。
因为中文是字符级的 tok,所以做 MLM 任务不是很理想,所以下面我用英文的 base 模型示例一个 MLM 任务:
from transformers import pipeline
# 运行该段代码要保障你的电脑能够上网,会自动下载预训练模型,大概420M
unmasker = pipeline("fill-mask",model = "bert-base-uncased") # 这里引入了一个任务叫fill-mask,该任务使用了base的bert模型
unmasker("The goal of life is [MASK].", top_k=5) # 输出mask的指,对应排名最前面的5个,也可以设置其他数字
# 输出结果如下,似乎都不怎么有效哈。
[{'score': 0.10933303833007812,
'token': 2166,
'token_str': 'life',
'sequence': 'the goal of life is life.'},
{'score': 0.03941883146762848,
'token': 7691,
'token_str': 'survival',
'sequence': 'the goal of life is survival.'},
{'score': 0.032930608838796616,
'token': 2293,
'token_str': 'love',
'sequence': 'the goal of life is love.'},
{'score': 0.030096106231212616,
'token': 4071,
'token_str': 'freedom',
'sequence': 'the goal of life is freedom.'},
{'score': 0.024967126548290253,
'token': 17839,
'token_str': 'simplicity',
'sequence': 'the goal of life is simplicity.'}]
3.6 后处理
后处理通常要根据你选择的模型来确定,一般模型的输出是 logits,其包含我们需要的语义信息,然后后处理是经过一个激活函数输出我们可以使用的向量,比如 softmax 层做二分类,会输出对应两个标签的概率值,然后就可以轻松转化为我们需要的信息啦。


